최근 공개 모델 시장에서 화제가 되는 DeepSeek v3는 607B 파라미터(Mixture-of-Experts, 이하 MoE 아키텍처)로 구성되어 있으나, 실제 활성화되는 파라미터는 37B에 불과해 강력하면서도 효율적인 오픈소스 LLM으로 평가받고 있습니다. 특히 GPT-4o나 Claude 3.5 Sonnet 같은 폐쇄형 대형 언어 모델과 어깨를 나란히 하거나, 특정 작업에서는 이를 앞지른다는 점에서 많은 관심을 받고 있습니다.
이 글에서는 DeepSeek v3의 핵심 특징부터 다른 모델들과의 성능 비교, 그리고 비용 대비 효율성까지 종합적으로 살펴보겠습니다.

주요 이슈
- 모델 구조: 607B 파라미터 중 매 토큰별 활성화되는 파라미터는 37B로, MoE 아키텍처를 활용해 계산량을 크게 줄임.
- 교육 비용: 약 6백만 달러(87억 원)로, 비슷한 규모 타 모델 대비 훈련 비용이 매우 낮음.
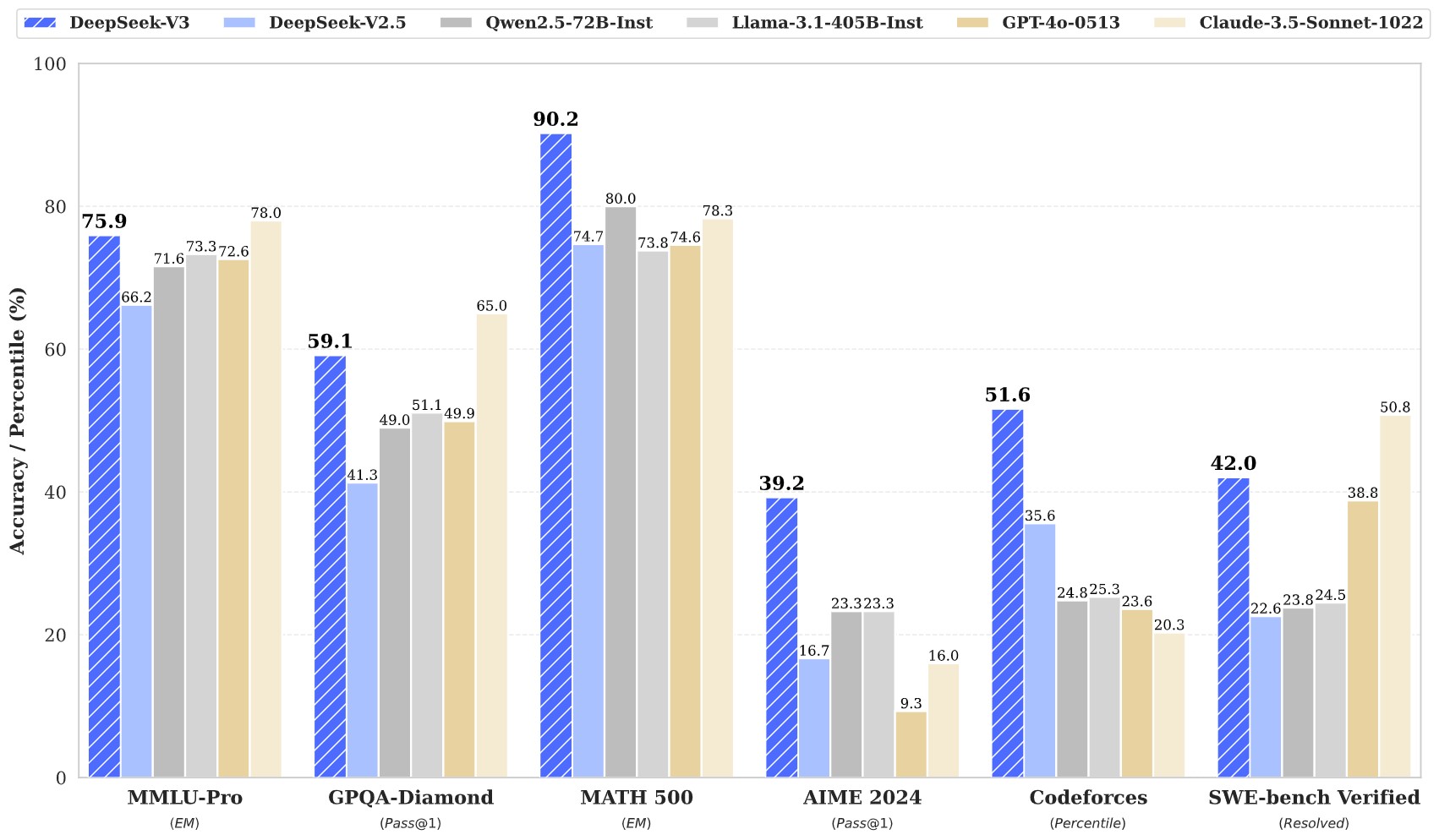
- 성능 지표:
- 추론(Reasoning): GPT-4o와 Claude 3.5 Sonnet과 비슷하거나 우위
- ㆍ 수학(Math): GPT-4o, Claude 3.5 Sonnet보다 정확도 높음
- ㆍ 코딩(Coding): Claude 3.5 Sonnet보다는 다소 아쉬우나, GPT-4o와는 비슷
- ㆍ 창의적 글쓰기(Creative Writing): GPT-4o와 매우 유사한 결과물
- 가격 경쟁력: Claude 3.5 Sonnet이나 GPT-4o 수준의 성능을 훨씬 저렴한 비용으로 활용 가능

DeepSeek v3의 주요 특징
Mixture-of-Experts(MoE) 아키텍처
- 671B 파라미터 중 37B만 활성화: 밀집(dense) 모델 대비 연산량이 크게 감소하여, 대규모 모델에서도 빠른 추론을 지원
- Multi-head Latent Attention(MLA): Key-Value 캐시를 압축해, 메모리 사용량과 훈련 효율을 개선
FP8 혼합 정밀도(FP8 Mixed Precision) 훈련
- 메모리 사용량 50% 절감: 기존 FP16/FP32 포맷 대비 훨씬 적은 메모리로 대규모 학습이 가능
- 정밀도 유지: 세밀한 양자화 및 누적(accumulation) 정밀도 전략을 통해 모델 성능 손실 최소화
로드 밸런싱 전략
- 보조 손실(auxiliary-loss) 없이 구현: MoE 구조 내에서 부하 분산(Load Balancing)을 효율화해 성능 최적화 및 모델 안정성 향상
HAI-LLM 프레임워크
- DualPipe 알고리즘: 파이프라인 병렬 처리 시 발생하는 지연(bubble)을 줄이고, 계산과 통신을 중첩해 처리 속도 개선
- 효율적인 크로스-노드 all-to-all 통신: 네트워크 대역폭 활용 극대화
- 텐서 병렬 처리 최소화: 비용이 큰 텐서 병렬성을 지양해 메모리를 효율적으로 관리
DeepSeek v3 성능 및 실제 사례(Performance in Benchmarks)

추론(Reasoning)
- 일상적 질문부터 논리 퍼즐까지, DeepSeek v3는 GPT-4o, Claude 3.5 Sonnet과 비슷하거나 뛰어난 결과를 보임
- Farmer & Sheep 문제 같이 단순해 보이지만 오답이 잦은 퍼즐의 경우, o1 모델만 정답을 맞히긴 했지만, DeepSeek v3 역시 Claude 3.5 Sonnet, GPT-4o와 유사하게 접근
수학(Math)
- 단순 계산(예: 5.11 – 5.90)부터 고급 벡터/선형대수 문제(평행사변형의 가능한 네 번째 꼭짓점, GCD & LCM 응용 등)까지, GPT-4o와 Claude 3.5 Sonnet 대비 정확도가 높음
- 복잡한 문제에서도 추론 체인을 통해 답을 잘 도출하는 경향이 있음
코딩(Coding)
- LeetCode Hard 수준의 동적 프로그래밍 문제 등에서도 높은 정답률을 보여줌 – Claude 3.5 Sonnet이 여전히 약간 우세한 면이 있지만, GPT-4o와 비슷한 수준의 코딩 능력 확인
- 학습 가능성: 같은 문제를 두 번째 질의했을 때 해결 능력이 높아지는 등, 이미 해당 문제를 학습했을 가능성도 존재
창의적 글쓰기(Creative Writing)
- 출력 톤과 문단 구조가 GPT-4o와 매우 흡사
- 공식적이고 기업 친화적인 톤을 유지하는 경향이 있어, Claude 3.5 Sonnet처럼 독창적이거나 인간적인 느낌과는 약간 다름
- 비용 효율 측면에서는 높은 점수
비용 및 API 가격 정책
저비용 구조
- 하루 24시간, 초당 60 토큰(일반적인 인간의 5배 읽기 속도)으로 구동해도, 하루 약 2달러 정도라는 주장(Emad Mostaque)
- MoE, FP8, 커스텀 프레임워크 등 혁신으로 학습 비용을 600만 달러 선으로 억제
DeepSeek API 가격(2월 8일 이후)
- 입력(Input)
- 기본: $0.27 / 백만 토큰
- 캐시 히트(cache hit): \$0.07 / 백만 토큰
- 출력(Output)
- $1.10 / 백만 토큰
Claude 3.5 Sonnet나 GPT-4o 대비 대폭 저렴한 수준으로, AI 개발자 입장에서 비용 부담을 크게 덜어줌
Chain-of-Thought(CoT) 및 R1 증류(Distillation)
- DeepThink 기능: DeepSeek의 R1 시리즈 모델이 지닌 장문 추론(Chain-of-Thought) 능력을 v3에 통합
- Post-Training: DeepSeek-R1로부터 추론 패턴을 증류(distillation)해, DeepSeek v3의 추론 성능을 더욱 향상
- 출력 스타일 유지: R1의 검증(verification), 반영(reflection) 패턴을 추가하면서도, DeepSeek v3의 답변 톤이나 길이 조절 가능
모델 비교 요약
- 추론(Reasoning): DeepSeek v3 > Claude 3.5 Sonnet > GPT-4o
- 수학(Math): DeepSeek v3 > Claude 3.5 Sonnet > GPT-4o
- 코딩(Coding): Claude 3.5 Sonnet > DeepSeek v3 ≈ GPT-4o
- 창의적 글쓰기(Creative Writing): Claude 3.5 Sonnet > DeepSeek v3 ≈ GPT-4o
누가 DeepSeek v3를 선택해야 할까?
- 비용 대비 성능이 중요한 기업 및 개발자: GPT-4o 수준의 작업을 훨씬 낮은 비용으로 수행 가능
- 애플리케이션 개발: 대규모 트래픽을 처리해야 하는 사용자 인터페이스(챗봇, 생산성 앱 등)에 적합
- 온프레미스(자체 호스팅) 모델을 선호하는 경우: 오픈 가중치(Open-weight)로 자유도가 높고, 자체 서버에서 모델을 제어할 수 있음
결론
DeepSeek v3는 탁월한 추론 능력, 수학 해결 능력, 코딩 지원 능력을 가진 모델로, 특정 영역에서는 GPT-4o나 Claude 3.5 Sonnet을 능가하는 것으로 판단되며, 특히 훈련 비용 절감과 API 가격 경쟁력 면에서 AI 개발자들에게 매력적인 대안이 될 것으로 기대됩니다.
기존 폐쇄형 모델에 비해 오픈소스 특성과 비용 효율성을 동시에 추구하는 이들에게는 최적의 솔루션이 될 수 있습니다.
참고 자료: composio.dev, “Notes on the new Deepseek v3”