AI 환각 해결 방법을 묻는 사람이 많다. 그런데 아직도 많은 팀이 답을 거꾸로 찾는다. 모델을 더 길게 말하게 만든다. 프롬프트도 더 화려하게 쓴다. 자신감 있게 답하게 만든다. 그러면 정확도도 오를 거라 믿는다. 실제로는 반대다. 틀릴 때 멈추지 못하는 시스템은 위험하다. 잘 말하는 것과 정확한 것은 다르다.
2025년 9월 5일, OpenAI가 환각 연구 글을 공개했다. 이 글은 환각 문제를 선명하게 정리한다. 환각은 단순한 버그가 아니다. 추측에는 보상이 붙는다. 불확실성 표현에는 벌점이 붙는다. 이런 학습 구조가 환각을 키운다. 그래서 2026년 현재 중요한 질문은 달라졌다. “어떻게 더 많이 답하게 할까”가 아니다. “어떻게 모를 때 멈추게 할까”에 더 가깝다.

이 관점은 컨텍스트 엔지니어링 글과도 이어진다. 더 중요한 일이 있다. 답변이 나오는 환경을 설계하는 일이다.
왜 AI 환각 해결 방법의 출발점이 바뀌었나
많은 사람은 환각을 데이터 문제로 봤다. 파라미터 부족 문제로 보기도 했다. 모델이 더 커지면 자연스럽게 사라질 현상처럼 여겼다. 하지만 OpenAI 연구진의 논문 OpenAI 논문은 다른 지점을 짚었다.
핵심은 단순하다. 언어 모델은 모를 때도 찍는 쪽으로 자주 길들여진다. 그 편이 점수상 유리하기 때문이다. 벤치마크가 정확도만 보고 “모르겠다”를 0점 처리하면 어떻게 될까. 모델은 빈칸보다 추측을 택하는 쪽으로 학습된다. 시험장에서 모르는 문제를 찍는 학생과 비슷하다. 조금이라도 맞을 가능성이 있으면 찍는 편이 유리하다.
이 설명이 중요한 이유는 분명하다. 문제의 위치를 바꿔주기 때문이다. 환각은 말투의 문제가 아니다. 인센티브의 문제다. 질문 문장만 고쳐서는 한계가 뚜렷하다. 질문 대신 세계를 짓는 법도 이 문제를 다룬다. 시스템이 어떤 기준으로 말하는지 먼저 정해야 한다. 언제 멈출지도 같이 정해야 한다.
모델이 더 똑똑해져도 환각이 남는 이유
여기서 많은 사람이 또 오해한다. “그럼 더 좋은 모델이 나오면 해결되는 것 아닌가?” 맞는 말이다. 다만 절반만 맞다.
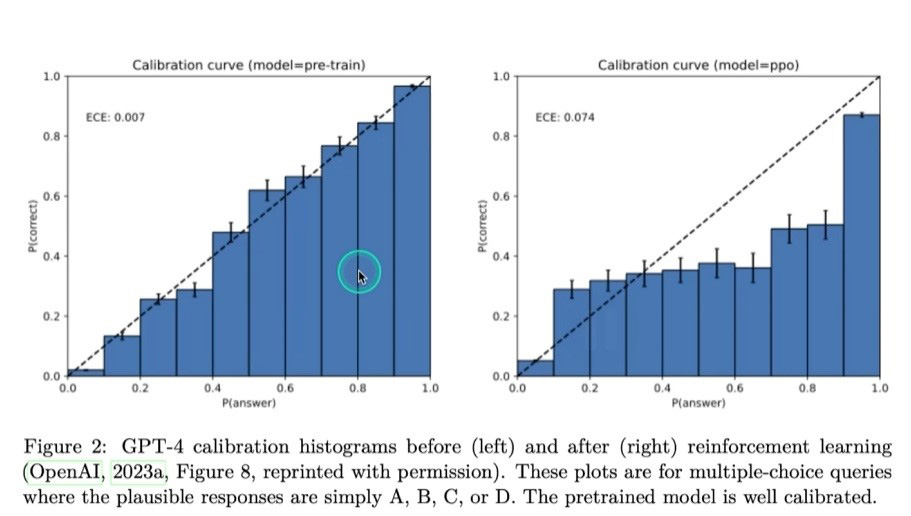
OpenAI는 2025년 2월 27일 GPT-4.5 소개를 공개했다. 설명은 분명했다. GPT-4.5는 지식 폭이 더 넓다. 의도 이해도 더 낫다. 그래서 환각도 줄어든다는 것이다. 실제로 더 나은 사전학습과 후처리는 도움이 된다. 패턴 인식이 좋아질수록 쉬운 사실 오류는 줄어든다.
문제는 불확실성이 큰 영역이다. 여기엔 저빈도 사실이 있다. 최신 정보도 있다. 맥락이 빈 질문도 여기에 들어간다. OpenAI 설명도 비슷하다. 규칙이 분명한 과제는 규모가 커질수록 잘 맞춘다. 철자나 괄호 짝이 대표적이다. 하지만 생일, 특정 이력, 실시간 수치는 다르다. 패턴만으로 추론하기 어려운 사실은 여전히 틀린다. 모델이 많이 알수록 문제는 더 교묘해진다. 애매한 경우에도 그럴듯한 후보를 능숙하게 만들어내기 때문이다.
대규모 코드베이스 글도 같은 이야기를 한다. AI 협업 전략도 마찬가지다. AI의 첫 답을 믿는 습관부터 버려야 한다. 근거를 먼저 확인하자. 작업 경계도 먼저 정하자.
2026년에는 정답률보다 멈추는 능력이 더 중요해졌다
2025년 10월 27일 공개된 Model Spec이 있다. 이 흐름은 그 문서에서 더 분명해졌다. 이 문서는 좋은 응답의 순서를 사실상 이렇게 정리한다. 가장 좋은 것은 확신 있는 정답이다. 그다음은 보류다. 틀린 답을 자신 있게 말하는 것보다 낫다.
이 기준은 추상적인 선언이 아니다. OpenAI가 2025년 9월 5일 글에서 든 SimpleQA 비교를 보자. gpt-5-thinking-mini는 o4-mini보다 정확도는 약간 낮았다. 하지만 오답률은 훨씬 낮았다. 이유는 간단했다. 모를 때 멈추는 비율이 높았기 때문이다. 정확도만 보면 손해처럼 보인다. 하지만 실무에서 더 치명적인 건 “틀린데 맞는 척하는 답”이다.
이 점이 중요하다. 그래서 2026년 AI 운영에서는 행동 규칙 설계가 더 중요해졌다. OpenAI는 2026년 3월 25일 Model Spec 접근법을 공개했다. 핵심은 모델 행동을 공개 프레임워크로 다루겠다는 것이다. 이제 업계는 답변량보다 멈추는 시점을 더 본다. 불확실성 전달도 제품 설계의 일부가 됐다.
실무에서 바로 쓰는 AI 환각 해결 방법 4가지
1. 답변 시스템과 검증 시스템을 분리하라
모든 질문에 바로 답하게 만들지 말자. 사실 확인이 필요한 질문은 따로 빼자. 검색 단계가 필요하다. 문서 조회 단계도 필요하다. 특히 위험한 정보가 있다. 최신 수치다. 인물 이력이다. 법률과 가격도 마찬가지다. 이런 정보는 생성만으로 처리하면 사고 난다.
에이전트 실무 가이드를 봐도 같은 흐름이 보인다. 실무형 에이전트는 거대 모델 하나에만 기대지 않는다. 단계를 나눠 처리한다. 환각을 줄이는 가장 현실적인 방법도 이 구조 분리다.
2. “모르겠다”를 실패로 취급하지 마라
팀 내부 평가표가 답변 개수와 속도만 보면 문제가 생긴다. 모델은 계속 무리해서 말하려 든다. 환각을 줄이고 싶다면 무응답과 오답을 다르게 다뤄야 한다. 무응답은 후속 탐색으로 복구할 수 있다. 하지만 자신감 있는 오답은 위험하다. 의사결정을 잘못된 방향으로 민다.
AI 도구와 인간 중심 설계도 같은 점을 짚는다. 속도만 기준이 되면 검증을 건너뛰게 된다. UI도 바뀌어야 한다. 운영 규칙도 같이 가야 한다.
3. 출처 없는 사실 답변은 기본적으로 의심하라
AI가 문장을 매끄럽게 말한다고 사실까지 검증된 건 아니다. 이 간극이 바로 환각의 무서운 지점이다. 그래서 사실성이 중요한 답변에는 출처 규칙이 필요하다. 가능하면 1차 출처를 쓰자.
이 점은 AI 챗봇 검색 전략과도 연결된다. AI가 웹을 읽고 요약하는 시대다. 검색 노출보다 더 중요한 게 있다. 원문에 닿을 수 있는가가 신뢰를 만든다.
4. 프롬프트보다 운영 루프를 점검하라
환각을 줄인다고 하면서 프롬프트만 계속 바꾸는 팀이 많다. 하지만 실무에서는 프롬프트보다 운영 루프가 더 중요하다. 누가 최종 검토하는지부터 정해야 한다. 어떤 질문에서 검색을 강제할지도 정해야 한다. 오답 사례를 어떻게 학습시킬지도 중요하다. 실패 로그를 어떻게 쌓을지도 결과를 바꾼다.
자동화 부채 경고도 같은 맥락이다. 검증 없는 자동화는 생산성이 아니라 부채가 된다.
바로 적용할 수 있는 점검표
-
AI 환각 대응 운영 체크리스트
- 최신 정보, 수치, 인물 이력 질문에 검색 단계를 강제하고 있는가?
- 모델이 “모르겠다”고 답해도 실패로 기록하지 않는가?
- 사실 판단이 필요한 출력에 출처 링크를 남기고 있는가?
- 원문 경로도 함께 남기고 있는가?
- 오답 사례를 프롬프트 수정만으로 덮지 않는가?
- 평가 기준도 함께 고치고 있는가?
- 고위험 답변에는 사람 검토 단계를 두고 있는가?
결국 신뢰를 만드는 건 정답률이 아니라 태도다
한 문장으로 정리하면 이렇다. 더 많이 말하게 만들지 말자. 모를 때 멈추게 만들어야 한다.
이건 소극적인 접근이 아니다. 더 강한 시스템 설계다. 정확한 답이 가능하면 자신 있게 말한다. 애매하면 불확실성을 밝힌다. 필요하면 도구로 넘긴다. 사람 검토도 붙인다. 좋은 AI는 뭐든 다 아는 척하지 않는다. 자신 있는 영역과 조심해야 할 영역을 구분한다.
사람은 틀릴 수 있는 AI 자체를 싫어하는 게 아니다. 틀렸는데도 안 틀린 척하는 AI를 싫어한다. 신뢰는 완벽함에서 나오지 않는다. 한계를 드러내는 방식에서 나온다.
참고 자료:
- OpenAI, Why language models hallucinate
- OpenAI, Why Language Models Hallucinate (paper)
- OpenAI, Model Spec (2025-10-27)
- OpenAI, Introducing GPT-4.5
- OpenAI, Inside our approach to the Model Spec