
오늘은 GPU 컴퓨팅의 미래를 혁신할 Vulkan 기반의 Kompute 프레임워크를 소개해드리겠습니다. Kompute는 초고속, 모바일 지원, 비동기식 처리 등을 통해 다양한 사용 사례에 최적화된 프레임워크로, 그래픽 카드를 사용하는 모든 애플리케이션에 새로운 가능성을 열어줍니다. 특히, Linux 재단의 후원 아래 강력한 기능을 갖춘 이 프레임워크가 어떻게 여러분의 프로젝트에 도움이 될 수 있을지 알아보겠습니다.
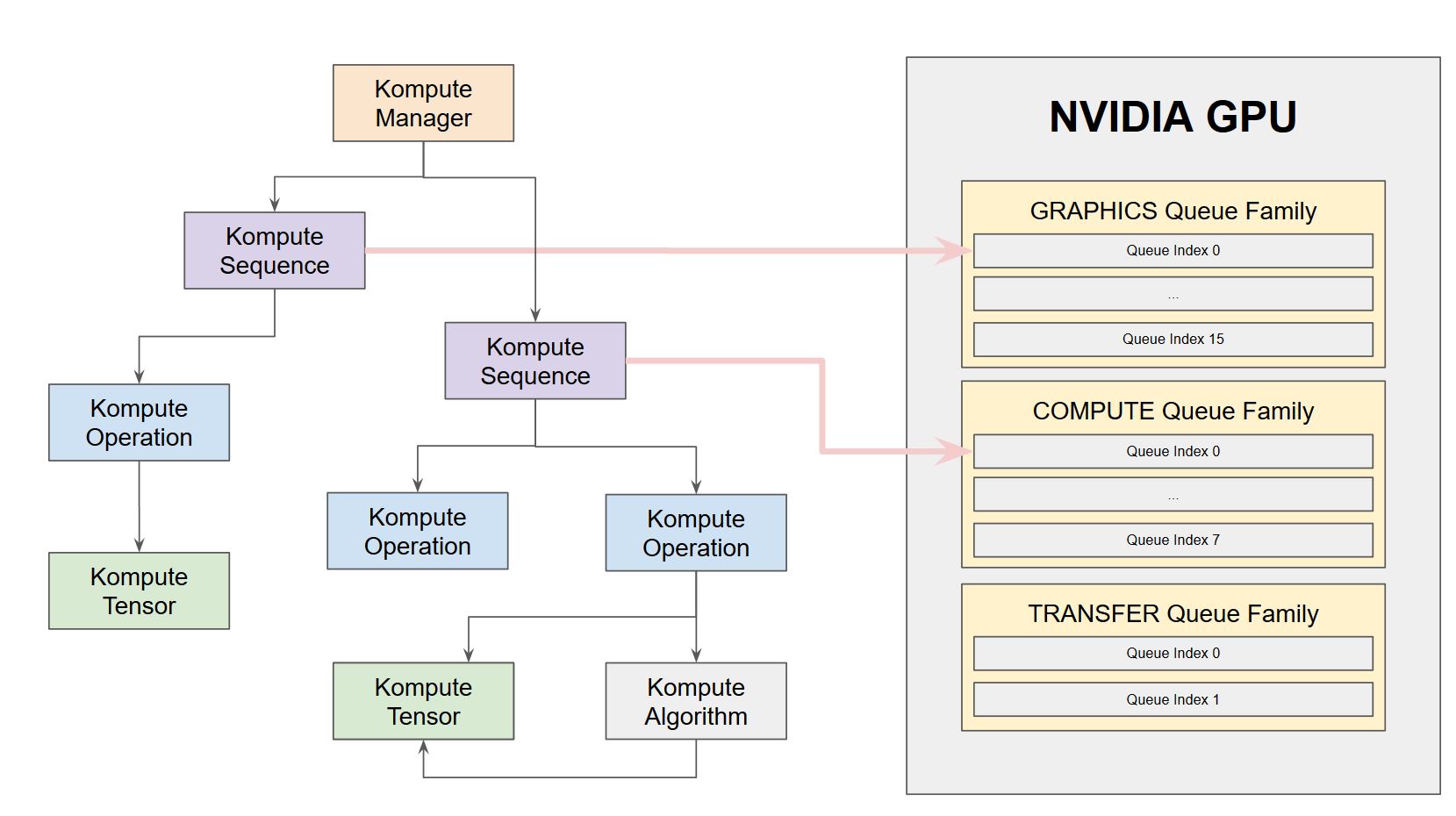
Kompute는 다양한 그래픽 카드를 지원하는 범용 GPU 계산 프레임워크로, 여러 아키텍처에서 Android NDK를 통해 모바일 지원도 가능합니다. 또한, BYOV(Bring-your-own-Vulkan) 설계를 통해 기존의 Vulkan 애플리케이션과 잘 통합됩니다. 가장 눈에 띄는 특징 중 하나는 90% 이상의 단위 테스트 코드 커버리지를 갖춘 강력한 코드베이스입니다. 이를 통해 개발자는 안정적이고 신뢰성 있는 환경에서 작업할 수 있습니다.
- 유연한 Python 모듈과 C++ SDK 제공
- 비동기 및 병렬 처리 지원
- 모바일 지원 및 Android NDK 예제 포함
- 기존 Vulkan 애플리케이션과 호환
- 90% 단위 테스트 코드 커버리지
사용 사례
Kompute를 사용하는 프로젝트들은 다양합니다. GPT4ALL은 CPU와 거의 모든 GPU에서 로컬로 실행되는 대규모 언어 모델 생태계를 제공합니다. llama.cpp는 Facebook의 LLaMA 모델을 C/C++로 포팅한 프로젝트이며, how-to-optimized-gemm은 행렬 곱셈 최적화를 다룹니다. 마지막으로, vkJAX는 Vulkan을 위한 JAX 인터프리터로, 이 모든 프로젝트가 Kompute의 유연성과 성능을 잘 보여줍니다.
다음은 C++와 Python을 사용한 간단한 GPU 곱셈 예제입니다. 이 예제는 Kompute의 기능을 활용하여 GPU에서 빠르게 계산을 수행하는 방법을 보여줍니다.
// C++ 예제 코드
#include <kompute/Kompute.hpp>
void kompute(const std::string& shader) {
kp::Manager mgr;
auto tensorInA = mgr.tensor({ 2., 2., 2. });
auto tensorInB = mgr.tensor({ 1., 2., 3. });
auto tensorOutA = mgr.tensorT<uint32_t>({ 0, 0, 0 });
auto tensorOutB = mgr.tensorT<uint32_t>({ 0, 0, 0 });
std::vector<std::shared_ptr<kp::Tensor>> params = {tensorInA, tensorInB, tensorOutA, tensorOutB};
kp::Workgroup workgroup({3, 1, 1});
std::vector<float> specConsts({ 2 });
std::vector<float> pushConstsA({ 2.0 });
std::vector<float> pushConstsB({ 3.0 });
auto algorithm = mgr.algorithm(params, compileSource(shader), workgroup, specConsts, pushConstsA);
mgr.sequence()
->record<kp::OpTensorSyncDevice>(params)
->record<kp::OpAlgoDispatch>(algorithm)
->eval()
->record<kp::OpAlgoDispatch>(algorithm, pushConstsB)
->eval();
auto sq = mgr.sequence();
sq->evalAsync<kp::OpTensorSyncLocal>(params);
sq->evalAwait();
for (const float& elem : tensorOutA->vector()) std::cout << elem << " ";
for (const float& elem : tensorOutB->vector()) std::cout << elem << " ";
}# Python 예제 코드
from kompute import Manager, Tensor, OpTensorSyncDevice, OpAlgoDispatch
def kompute(shader):
mgr = Manager()
tensor_in_a = mgr.tensor([2, 2, 2])
tensor_in_b = mgr.tensor([1, 2, 3])
tensor_out_a = mgr.tensor_t([0, 0, 0], dtype=np.uint32)
tensor_out_b = mgr.tensor_t([0, 0, 0], dtype=np.uint32)
params = [tensor_in_a, tensor_in_b, tensor_out_a, tensor_out_b]
workgroup = (3, 1, 1)
spec_consts = [2]
push_consts_a = [2]
push_consts_b = [3]
algo = mgr.algorithm(params, compile_source(shader), workgroup, spec_consts, push_consts_a)
(mgr.sequence()
.record(OpTensorSyncDevice(params))
.record(OpAlgoDispatch(algo))
.eval()
.record(OpAlgoDispatch(algo, push_consts_b))
.eval())
sq = mgr.sequence()
sq.eval_async(OpTensorSyncLocal(params))
sq.eval_await()
print(tensor_out_a)
print(tensor_out_b)
if __name__ == "__main__":
shader = """
#version 450
layout (local_size_x = 1) in;
layout(set = 0, binding = 0) buffer buf_in_a { float in_a[]; };
layout(set = 0, binding = 1) buffer buf_in_b { float in_b[]; };
layout(set = 0, binding = 2) buffer buf_out_a { uint out_a[]; };
layout(set = 0, binding = 3) buffer buf_out_b { uint out_b[]; };
layout(push_constant) uniform PushConstants { float val; } push_const;
layout(constant_id = 0) const float const_one = 0;
void main() {
uint index = gl_GlobalInvocationID.x;
out_a[index] += uint(in_a[index] * in_b[index]);
out_b[index] += uint(const_one * push_const.val);
}
"""
kompute(shader)결론
Kompute는 여러분의 GPU 컴퓨팅 경험을 한 단계 업그레이드할 준비가 되어 있습니다. 초고속 성능, 유연한 모듈성, 다양한 지원 기능 등을 통해 여러분의 프로젝트를 더 빠르고 효율적으로 만들어 줄 것입니다. 지금 바로 Kompute를 도입하여 그 가능성을 직접 체험해보세요! 독자 여러분의 성공적인 프로젝트를 응원합니다.
참고 자료: GitHub, “Kompute”@link=https://github.com/KomputeProject/kompute&target=_blank]