
지난 몇 년 동안 우리는 오픈소스 AI의 놀라운 발전을 목격해왔습니다. 특히 대규모 언어 모델 분야에서 눈부신 성장을 이루었는데, 2022년에 출시된 OpenAI의 ChatGPT는 많은 이목을 끌기도 했습니다. 이후로도 연구 및 상업적 용도로 다양한 고성능 오픈소스 LLM이 등장하고 있는데, 이러한 오픈소스 LLM 모델들은 GPT4와 같은 독점 AI 모델에 필적하지는 못하지만, GPT 3.5와 같은 이전 세대 모델에 비해 획기적인 발전을 보여주고 있습니다.
그렇다면, 2024년에 주목해야 할 오픈소스 LLM은 과연 무엇일까요? 이 글에서는 오픈소스 AI 생태계의 최신 동향을 반영하여 여러분이 주목해야 할 6가지 LLM을 소개해드리겠습니다.
1. Meta의 Llama 2: 범용성과 성능의 결합
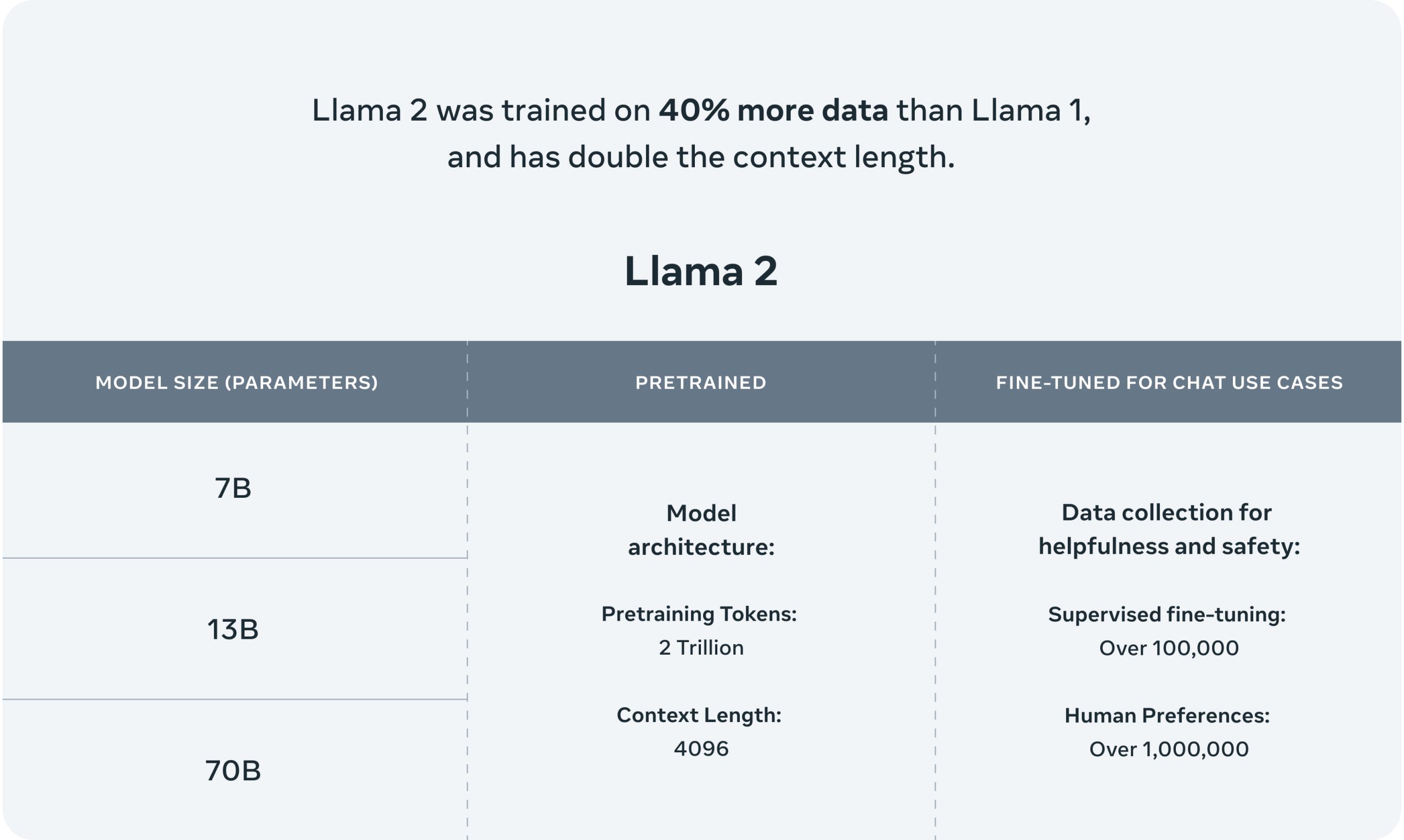
올해 우리가 주목해야 할 가장 중요한 오픈소스 LLM 중 하나는 바로 Meta의 Llama 2입니다. 이 모델은 그 범용성과 성능 면에서 상업적 활용에 최적화된 오픈소스 LLM으로 평가받고 있습니다. 지난 7월, Meta와 Microsoft가 함께 발표한 라마 2는 2조 개의 토큰으로 학습된 사전 학습된 생성형 AI 모델이며, 70억~700억 개의 매개변수를 지원합니다. 라마 2는 라마 1에 비해 40% 더 많은 데이터로 학습되었고, 두 배의 컨텍스트 길이를 지원하는 것이 특징입니다.
라마 2는 현재 시장에서 가장 성능이 뛰어난 오픈소스 언어 모델 중 하나로 인정받고 있습니다. 허깅 페이스 오픈 LLM 리더보드에서는 평균 67.35점을 기록한 라마 2 70B가 2위를 차지하며 ARC 67.32점, 헬라스웨그 87.33점, MMLU 69.83점, 트루스풀큐에이 44.92점을 기록한 다른 모델들을 능가했습니다.
Llama 2의 경쟁력은 GPT4에 버금가는 성능
라마 2는 GPT4와 같은 독점 모델에 대해서도 유망한 성능을 보여주었습니다. 애니스케일의 수석 과학자이자 Google의 전 수석 엔지니어인 Waleed Kadous는 라마 2의 요약 정확도가 GPT4와 거의 동일한 수준이면서, 실행 비용은 30배 더 저렴하다고 밝혔습니다.
메타는 긴 쿼리에 대한 더욱 우수한 응답을 위해 새로운 버전의 라마 2도 개발했습니다. 이 수정 버전은 4,000억 개의 토큰이 추가되고 32,000개의 컨텍스트 길이를 지원합니다. 출시 당시 Meta는 Llama 2 Long의 70B 버전이 질문에 대한 답변, 테스트 요약, 다중 문서 집계 등의 긴 컨텍스트 작업에서 GPT 3.5 16ks 성능을 능가한다고 주장했습니다.
Llama 2의 장점과 단점
Llama 2는 여러 면에서 뛰어난 성능을 자랑합니다. 자연어 생성, 채팅 사용 사례에 맞는 미세 조정, 단발성 학습, 멀티태스크 학습 등 다양한 분야에서 높은 성능을 보여줍니다. 또한, 비슷한 규모의 LLM에 비해 적은 컴퓨팅 리소스를 사용하며, 여러 언어로 번역 및 여러 프로그래밍 언어를 지원하고, 더 안전한 출력을 생성합니다. 이 모델은 1백만 개가 넘는 사람 주석을 포함한 다양한 데이터 세트를 사용해 학습됩니다.
하지만, 단점도 있습니다. 교육은 재정적, 전산적으로 많은 비용이 소요될 수 있으며, GPT 3.5와 같은 모델만큼 창의적이지 않다는 평가를 받기도 합니다. 영어 이외의 언어 지원은 제한적이며, 성능은 사전 학습 데이터의 품질에 따라 달라질 수 있습니다. 또한, AI 환각과 같은 문제도 발생할 수 있습니다.
2. Falcon 180B: 파워풀한 오픈 엑세스 모델
2023년에 우리가 주목해야 할 또 다른 중요한 LLM은 바로 Falcon 180B입니다. 이는 아랍에미리트 기술 혁신 연구소에서 개발된 모델로, 최대 1,800억 개의 파라미터를 지원하고 RefinedWeb 데이터 세트에서 가져온 3조 5,000억 개의 토큰으로 학습되었습니다. 자연어 처리 작업에서 뛰어난 성능을 보이며, 현재 Hugging Face Open LLM 리더보드에서 평균 68.74점을 기록하고 있습니다. 이는 ARC에서 69.8점, HellaSwag에서 88.95점, MMLU에서 70.54점, TruthfulQA에서 45.67점을 획득하며 1위를 차지한 점수입니다.
TII는 Falcon 180B가 추론, 코딩 능력, 지식 테스트에서 “매우 우수한 성능”을 보여주었다고 주장합니다. 이에 따르면, Falcon 180B는 라마 2와 같은 경쟁 모델을 능가하며, 구글의 PaLM 2로 구동되는 인기 있는 바드 챗봇과 동등한 수준의 성능을 보여준다고 합니다.
챗봇 컨텍스트의 Falcon 180B
챗봇과 명령어 데이터에 맞게 조정된 Falcon 180B의 수정 버전인 Falcon 180B Chat은 연구자들이 실험할 수 있도록 설계되었습니다. 이는 특히 채팅 애플리케이션에 최적화된 모델로, 사용자와의 대화에서 높은 수준의 응답 능력을 제공합니다.
Falcon 180B의 제한 사항
Falcon 180B는 몇 가지 중요한 제한 사항을 가지고 있는데, 기본 라이선스가 상당히 제한적인 것이 가장 큰 단점입니다. TII는 현지 또는 국제법을 위반하거나 다른 생명체에 해를 끼치는 행위를 금지하고 있으며, 관리자 서비스를 호스팅하거나 제공하려면 별도의 라이선스가 필요합니다. 또한, Falcon 180B는 다른 독점 LLM이나 라마 2와 같은 세밀하게 조정된 오픈소스 LLM에 비해 가드레일이 부족하여 악의적인 사용 사례에 더 쉽게 사용될 수 있습니다.
Falcon 180B의 장점과 단점
Falcon 180B의 장점으로는 GPT 3.5 및 Llama 2와 같은 인기 있는 도구보다 더 강력하다는 점, 텍스트 생성 및 코드 작성, 추론에 최적화되어 있다는 점, 연구 및 상업적 용도로 사용 가능하다는 점 등이 있습니다. 또한, 채팅 및 인스트럭션 데이터에 대한 미세 조정 능력과 다양한 데이터에 대한 학습 능력도 장점으로 꼽힙니다.
하지만, 오픈 소스가 아닌 오픈 액세스 모델이라는 점이 가장 큰 단점이며, 상업적 사용에 대한 제한, 강력한 하드웨어가 필요하다는 점, 시중의 다른 도구만큼 사용자 친화적이지 않다는 점 등이 단점으로 꼽히고 있습니다. 또한, 모델에 대한 호스팅 액세스를 제공하기 전에 TII에 문의해야 하는 절차도 필요합니다.

3. Code Llama: 메타의 혁신
2023년에 주목받는 오픈 LLM 모델 중 하나는 메타의 Code Llama입니다. 이 모델은 코드 생성에 특화되어 있으며, 5,000억 개의 코드 토큰과 코드 관련 데이터 세트를 기반으로 학습되었습니다. Code Llama는 7B, 13B, 34B 매개변수를 지원하며, Python, C++, Java, PHP, Typescript(자바스크립트), C#, Bash 등 다양한 프로그래밍 언어로 코드를 생성하고, 그 코드가 수행하는 작업을 설명할 수 있도록 미세 조정되었습니다.
예를 들어, 사용자는 Code Llama를 통해 피보나치 수열을 출력하는 함수를 작성하거나 특정 디렉토리의 모든 텍스트 파일을 나열하는 방법에 대한 지침을 요청할 수 있습니다. 이러한 능력은 워크플로를 간소화하려는 개발자나 코드의 기능과 작동 방식을 더 잘 이해하고자 하는 초보 코더에게 매우 유용합니다.
Code Llama는 크게 두 가지 버전으로 나뉩니다.
- Code Llama Python
- Code Llama Instruct
Code Llama Python은 Python 프로그래밍 언어에 대한 코드 작성 능력을 강화하기 위해 추가로 1,000억 개의 Python 코드 토큰을 학습시킨 버전입니다. 반면, Code Llama Instruct는 50억 개의 인간 명령어 토큰으로 학습된 미세 조정 버전으로, 인간의 명령어를 더 잘 이해하도록 개발되었습니다.
Code Llama의 장점과 단점
Code Llama의 장점으로는 자연어 및 코드 생성이 가능하다는 점, 채팅 사용 사례에 사용할 수 있는 미세 조정된 모델 버전(Mistral 7B Instruct)이 있으며, 추론 시간 단축(그룹화된 쿼리 관심도 활용), 추론 비용 절감(슬라이딩 윈도우 관심도 활용) 등이 있습니다. 또한, Code Llama는 로컬에서 사용 가능하며, Apache 2.0 라이선스에 따른 제한이 없습니다.
하지만, 단점으로는 추가적인 미세 조정 없이는 코딩 성능이 GPT-4보다 뒤떨어질 수 있다는 점, 제한된 매개변수, 즉각적인 주사의 위험, 환각이 발생하기 쉬운 점 등이 있습니다. 이러한 단점들은 특히 복잡한 코딩 작업이나 고급 개발 환경에서 사용할 때 고려해야 할 요소입니다.

4. Mistral 7B: 고성능 오픈 소스 LLM
2023년 9월, Mistral AI는 상당히 주목받은 LLM인 Mistral 7B를 출시했습니다. 이 모델은 70억 개의 파라미터를 가지고 있으며, 대규모 폐쇄 소스 모델보다 더 효율적으로 작동하도록 설계되었습니다. Mistral 7B는 실시간 애플리케이션 지원에 이상적이며, 그룹화된 쿼리 주의와 슬라이딩 윈도우 주의를 통해 더 빠른 추론과 더 긴 시퀀스를 더 낮은 비용으로 처리합니다.
이러한 기능 덕분에 Mistral 7B는 리소스 집약적인 LLM보다 더 낮은 비용으로 대용량 텍스트를 더 빠르게 처리하고 생성할 수 있습니다.
Mistral AI의 발표에 따르면, Mistral 7B는 다양한 벤치마크에서 뛰어난 성과를 보였습니다. ARC-e에서 80.0%, HellaSwag에서 81.3%, MMLU에서 60.1%, HumanEval 벤치마크 테스트에서 30.5%를 기록하여, 각 분야에서 Llama 2 7B를 크게 앞질렀습니다. 또한 코드, 수학, 추론 분야에서 Llama 1 34B를 능가하며, 코드 작업에서는 Code Llama 7B의 성능에 근접했습니다.
Mistral 7B의 장점과 단점
Mistral 7B의 장점으로는 자연어 및 코드 생성 능력, 채팅 사용 사례에 사용할 수 있는 미세 조정된 모델 버전(Mistral 7B Instruct), 빠른 추론 시간, 추론 비용 절감, 로컬에서의 사용 가능성, Apache 2.0 라이선스에 따른 제한 없음 등이 있습니다.
그러나 미세 조정 없이는 코딩 성능이 GPT-4보다 뒤처질 수 있으며, 제한된 매개변수, 프롬프트 주입에 노출될 위험, 환각 발생 가능성 등이 단접으로 꼽히고 있습니다. 특히, 일부 전문가들은 Mistral 7B의 콘텐츠 관리 부족으로 인해 폭탄 제작 방법 설명과 같은 문제가 있는 콘텐츠가 생성될 수 있다는 우려를 표명했습니다.
5. Vicuna 13B: 효율성과 정교함의 조화
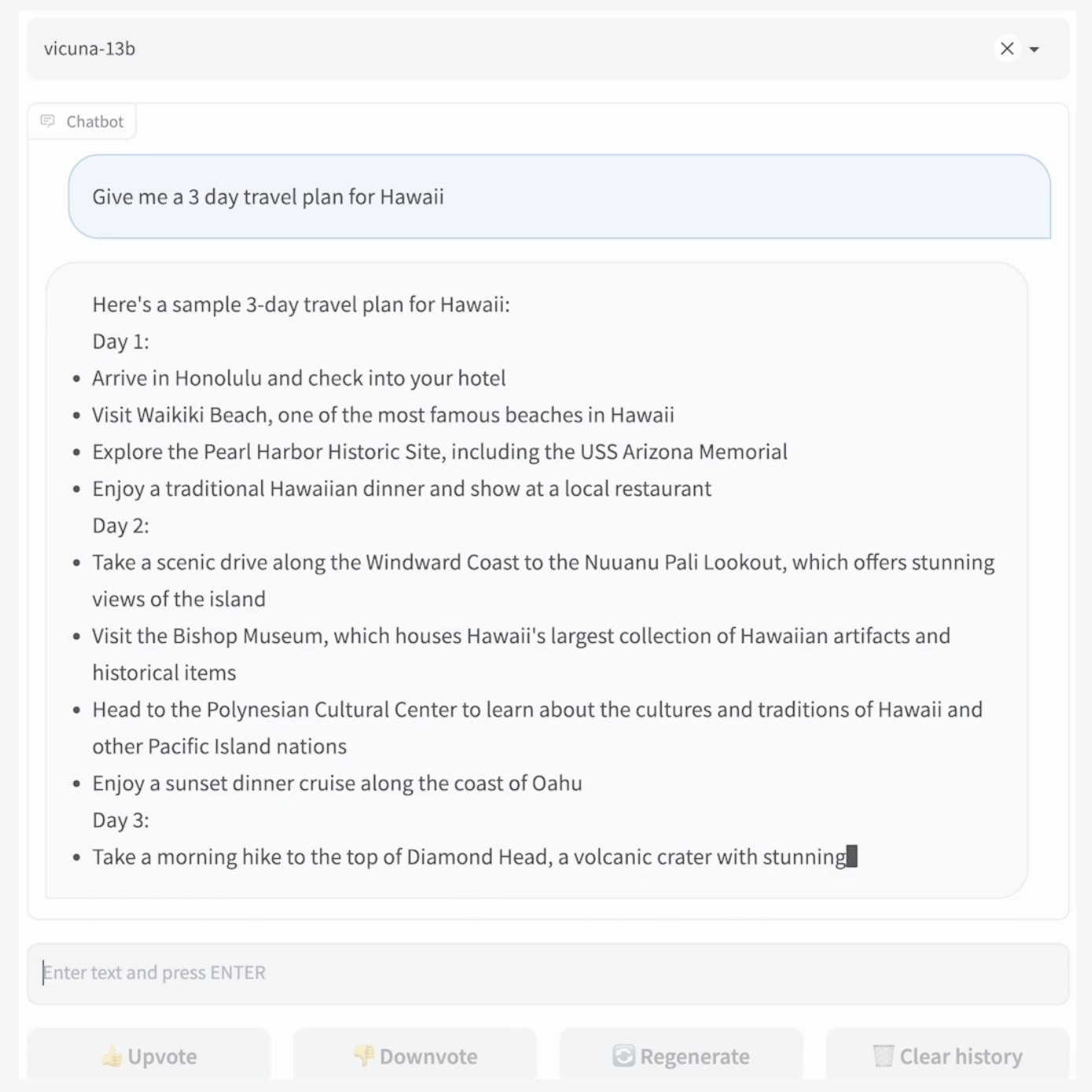
2023년 3월, UC 버클리의 학생과 교수진이 참여하는 대형 모델 시스템 조직에서 Vicuna 13B라는 오픈 소스 챗봇을 선보였습니다. Vicuna 13B는 메타의 라마 모델을 ShareGPT.com에서 사용자들이 공유한 70,000건의 ChatGPT 대화로 미세 조정하여 개발되었습니다. 이를 통해 Vicuna는 사용자의 질문에 대해 ChatGPT에 필적하는 수준의 정교함으로 상세하고 명료한 답변을 생성할 수 있게 되었습니다.
LMSYS 조직의 예비 테스트에 따르면, Vicuna는 90%의 시나리오에서 Llama와 Stanford Alpaca의 성능을 능가하면서 ChatGPT와 Bard의 90%의 품질을 달성했습니다. 이는 Vicuna 13B의 뛰어난 성능을 보여주는 결과입니다.
LMSYS Org는 또한 Vicuna 13B가 MT 벤치에서 6.39, 1,061 경기장 ELO 등급, MMLU에서 52.1을 달성했다고 보고했습니다. AlpacaEval 리더보드에서는 Vicuna 13B가 82.11%의 승률을 기록했으며, 이는 GPT-3.5의 81.71%, Llama 2 Chat 70B의 92.66%에 비해 월등히 높은 수치입니다. 특히, Vicuna 13B의 훈련 비용이 약 300달러였다는 점은 이러한 성과를 더욱 인상적으로 만듭니다.
Vicuna 13B와 Vicuna-33B
Vicuna 13B 외에도 더 큰 버전인 Vicuna-33B가 있으며, 이 제품은 MT 벤치에서 7.12점, MMLU에서 59.2점을 기록했습니다.
Vicuna의 장점과 단점
Vicuna 13B의 장점으로는 상세한 자연어 출력 생성, 경량성, 훈련 비용이 300달러라는 저렴함, ShareGPT에서 가져온 70,000개 이상의 대화로 미세 조정됨, 상업적 사용 가능성 등이 있습니다.
그러나 단점으로 추론 및 수학과 관련된 작업 수행에 제한이 있으며, 환각 발생 가능성, 제한된 콘텐츠 중재 제어 등이 꼽히고 있습니다. 이러한 제한 사항들은 특히 복잡한 문제 해결이나 민감한 콘텐츠 처리 시 고려해야 할 요소입니다.
Giraffe 70B: 컨텍스트 길이의 새로운 지평
2023년 9월, Abacus.AI는 Llama 2를 기반으로 한 AI 모델 제품군인 Giraffe의 70B 버전을 선보였습니다. 이 모델의 가장 큰 특징은 모델의 컨텍스트 길이를 4,096개에서 무려 32,000개로 확장한 것입니다. Abacus.AI는 Giraffe에 긴 컨텍스트 창을 제공하여 다운스트림 처리 작업의 성능을 개선했습니다.
이 컨텍스트 길이의 확장은 LLM이 오류를 줄이고 다운스트림 데이터 세트에서 더 많은 정보를 검색할 수 있게 하며, 사용자와의 더 긴 대화 유지에도 도움이 됩니다.
Abacus.AI는 Giraffe가 추출, 코딩, 수학 분야에서 모든 오픈 소스 모델 중 최고의 성능을 보여준다고 주장합니다. MT-Bench 평가 벤치마크에서 Giraffe 70B는 7.01점을 기록했습니다.
Abacus AI의 CEO 빈두 레디는 “우리는 긴 컨텍스트에서 LLM 성능을 조사하는 벤치마크 세트에서 70B 모델을 평가했다”고 말했습니다. 70B 모델은 문서 QA 작업에서 가장 긴 컨텍스트 창(32k)에서 13B 모델에 비해 크게 개선되어, AltQA 데이터 세트에서 61%의 정확도를 기록했으며, 13B 모델은 18%의 정확도에 그쳤다고 합니다.
또한 Abacus AI는 Giraffe 16k 모델이 최대 16,000개의 컨텍스트 길이까지 실제 작업에서 잘 작동하며, 잠재적으로 20~24,000개의 컨텍스트 길이까지 가능하다고 보고했습니다.
Giraffe의 장점과 단점
Giraffe 70B의 장점으로는 자연어 텍스트의 이해 및 생성, 큰 컨텍스트 창을 통한 더 큰 입력과 더 긴 대화 지원, 16K 컨텍스트 길이의 작업에서 우수한 성능 발휘 등이 있습니다.
그러나 단점으로 상당한 연산 능력이 필요하다는 점, 검색 정확도에 대한 미세 조정 필요성, 환각 발생 가능성 등이 꼽히고 있습니다. 특히, 큰 컨텍스트 길이와 관련된 복잡한 작업을 처리하기 위해서는 강력한 하드웨어 지원이 필수적입니다.

마치며
오늘 살펴본 여섯 가지의 오픈소스 LLM은 단순히 빙산의 일각에 불과하지만, 이들 모델은 오픈소스 AI 솔루션의 범위가 얼마나 빠르게 성장하고 있는지를 명확하게 보여주고 있습니다. 이러한 모델들은 오픈소스로 개발되어 자유롭게 사용할 수 있으며, 각 모델은 특정 분야에서 뛰어난 성능을 보여주고 있습니다.
2024년이 되면서, 오픈소스 LLM에 대한 관심은 더욱 증가할 것으로 보이며, 이러한 모델들의 반복적인 출시와 지속적인 미세 조정으로 인해, 이러한 솔루션의 유용성은 앞으로도 계속 확대될 것입니다. 개발자, 연구자, 그리고 일반 사용자들은 다양한 요구와 목적에 맞는 모델을 선택하여, 그들의 작업을 효율적이고 혁신적인 방법으로 수행할 수 있게 될 것입니다.
오픈소스 LLM은 단순히 기술의 진보를 넘어서, 지식의 민주화와 기술 접근성의 증대라는 큰 의미를 지니고 있습니다. 누구나 접근할 수 있는 이러한 도구들은 다양한 분야에서 새로운 가능성을 열어주고, 더 넓은 범위의 사람들이 AI의 혜택을 경험할 수 있게 만들 것입니다.
결국, 이러한 오픈소스 LLM의 발전은 기술적인 진보뿐만 아니라, 사회적, 교육적, 그리고 경제적으로도 중요한 영향을 미칠 것으로 기대됩니다. 2024년에 우리가 지켜볼 오픈소스 LLM의 세계는 단순히 기술의 발전을 넘어서, 지능적인 AI 솔루션의 새로운 지평을 여는 역사적인 순간이 될 것으로 기대됩니다.
참고 자료: Tim Keary, “6 Best Open-Source LLMs to Watch Out For in 2024”