
HTML에서 마크다운으로 변환하는 작업은 생각보다 쉽지 않습니다. 웹 콘텐츠는 복잡한 구조와 노이즈가 많아 이를 깔끔하게 추출하고 변환하는 것은 많은 기술적 도전 과제를 안고 있습니다. 이런 문제를 해결하기 위해 Jina AI는 HTML을 마크다운으로 변환하는 소형 언어 모델(SLM)인 Reader-LM을 출시했습니다. 이 모델은 HTML의 주요 콘텐츠를 선택적으로 복사(selective-copy)하여 마크다운으로 변환하는데 최적화되어 있으며, 특히 긴 문맥을 지원하는 것이 특징입니다.
Reader-LM의 등장 배경
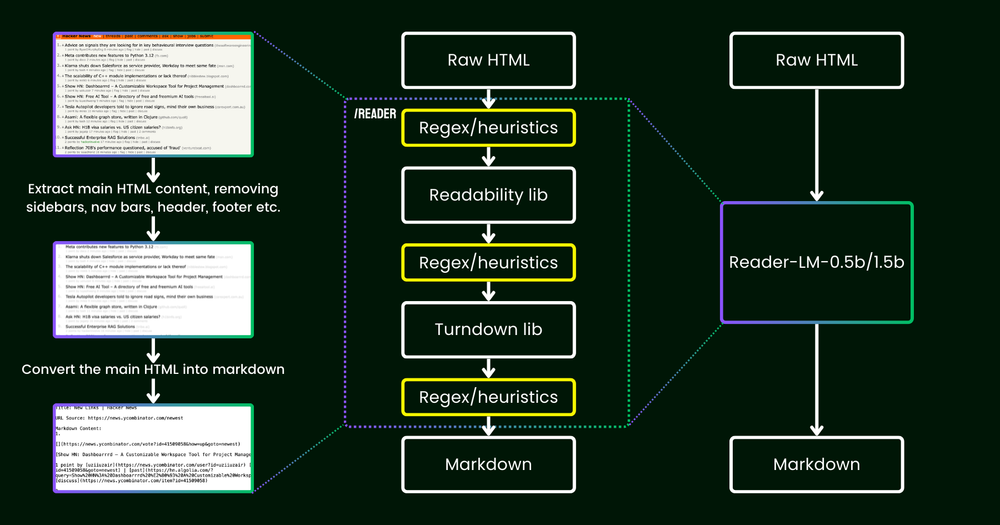
2024년 4월, Jina AI는 웹페이지 URL을 마크다운으로 변환하는 API인 Jina Reader를 선보였습니다. 이 API는 Chrome 브라우저로 웹페이지 소스를 가져와 Readability 패키지를 통해 메인 콘텐츠를 추출한 후, regex와 Turndown 라이브러리를 사용해 HTML을 마크다운으로 변환하는 방식으로 작동했습니다.
하지만 기존의 방법론은 정확도가 떨어지는 경우가 있었습니다. 특히 Readability 필터가 잘못된 콘텐츠를 제거하지 못하거나, Turndown이 특정 HTML 태그를 마크다운으로 변환하는 데 어려움을 겪었습니다. 이와 같은 문제를 해결하고자, Jina AI는 자체 소형 언어 모델을 통해 HTML에서 마크다운으로 변환하는 방법을 고민하게 되었습니다.
Reader-LM의 기술적 특징
HTML을 마크다운으로 변환하는 작업은 창의적인 문제라기보다는 입력에서 출력으로의 선택적 복사 작업입니다. 따라서 Jina AI는 대형 모델보다는 “shallow-but-wide”한 구조의 소형 언어 모델을 채택했습니다. 이는 변환 작업에 필요한 transformer block 수를 줄여 효율성을 높이는 데 중점을 둔 것입니다. Reader-LM은 두 가지 버전으로 제공됩니다.
- reader-lm-0.5b: 494M 파라미터를 가진 모델
- reader-lm-1.5b: 1.54B 파라미터를 가진 모델
특히 긴 문맥을 지원하기 위해 256K 토큰까지 처리할 수 있습니다. 일반적인 웹페이지 소스가 복잡하고 길기 때문에, 긴 문맥을 다룰 수 있는 기능은 필수적입니다.

Reader-LM 성능
Reader-LM은 여러 메트릭을 통해 평가되었습니다. 그 중에서도 ROUGE-L과 Token Error Rate(TER), Word Error Rate(WER) 등의 지표에서 우수한 성능을 보였습니다. 특히 reader-lm-1.5b는 ROUGE-L 0.72, WER 1.87로, 경쟁 모델을 압도하는 성능을 자랑했습니다. 실제 웹페이지를 마크다운으로 변환한 결과를 시각적으로 검사했을 때도, reader-lm-1.5b는 헤더 추출, 메인 콘텐츠 유지, 마크다운 문법 사용 등에서 뛰어난 성능을 보여주었습니다.
Reader-LM의 주요 성능 결과:
- ROUGE-L: 0.72
- WER: 1.87
상용화 및 활용 가능성
Reader-LM은 상용 환경에서의 사용도 고려하여 개발되었습니다. Jina AI는 Google Colab을 통해 reader-lm을 체험해볼 수 있는 노트북을 제공하고 있으며, Hacker News 웹사이트의 콘텐츠를 마크다운으로 변환하는 과정을 시연하고 있습니다. 상용 환경에서는 RTX 3090/4090 등의 고성능 GPU를 사용하는 것이 권장됩니다.
Jina AI는 Azure Marketplace와 AWS SageMaker에서도 Reader-LM을 제공할 예정입니다. 상용 라이선스는 CC BY-NC 4.0이며, 상업적 사용에 대해서는 별도의 문의가 필요합니다.
향후 과제와 개선 방향
Reader-LM은 이미 우수한 성능을 보여주고 있지만, 개선할 여지는 여전히 남아 있습니다. Jina AI는 앞으로 모델의 문맥 길이 확장과 디코딩 속도 향상, 그리고 명령어 지원 기능 등을 추가할 계획입니다. 또한, HTML 콘텐츠의 특성상 노이즈가 많고 구조가 복잡하기 때문에 이를 더 효율적으로 처리할 수 있는 새로운 방법들도 연구되고 있습니다.
결론
Reader-LM은 웹 데이터 추출과 마크다운 변환 작업에서 독보적인 성능을 자랑하는 소형 언어 모델입니다. 대형 LLM보다 더 적은 자원을 사용하면서도 긴 문맥을 처리할 수 있어, 웹 데이터를 다루는 많은 분야에서 실용적인 솔루션으로 자리잡을 가능성이 큽니다. 앞으로도 Reader-LM의 발전 가능성은 매우 크며, Jina AI는 이를 통해 웹 데이터 처리의 혁신을 계속 이어나갈 것입니다. Reader-LM은 웹 데이터를 다루는 사람들에게 최적의 선택이 될 것입니다.
참고 자료: Jina AI, “Reader-LM: Small Language Models for Cleaning and Converting HTML to Markdown”