PostgreSQL에서 UUID를 기본 키로 사용하는 방법에 대해 알아보겠습니다. UUID는 생성하기 쉽고, 분산 시스템 간에 공유하기 쉬우며 고유성을 보장하지만, 크기와 성능 측면에서 고민이 많습니다. 이 글에서는 PostgreSQL에서 UUID를 기본 키로 사용할 때의 효율적인 방법을 다루며, 특히 UUID v7을 사용하여 성능을 최적화하는 방법에 대해 소개해드리겠습니다.

UUID란 무엇인가요?
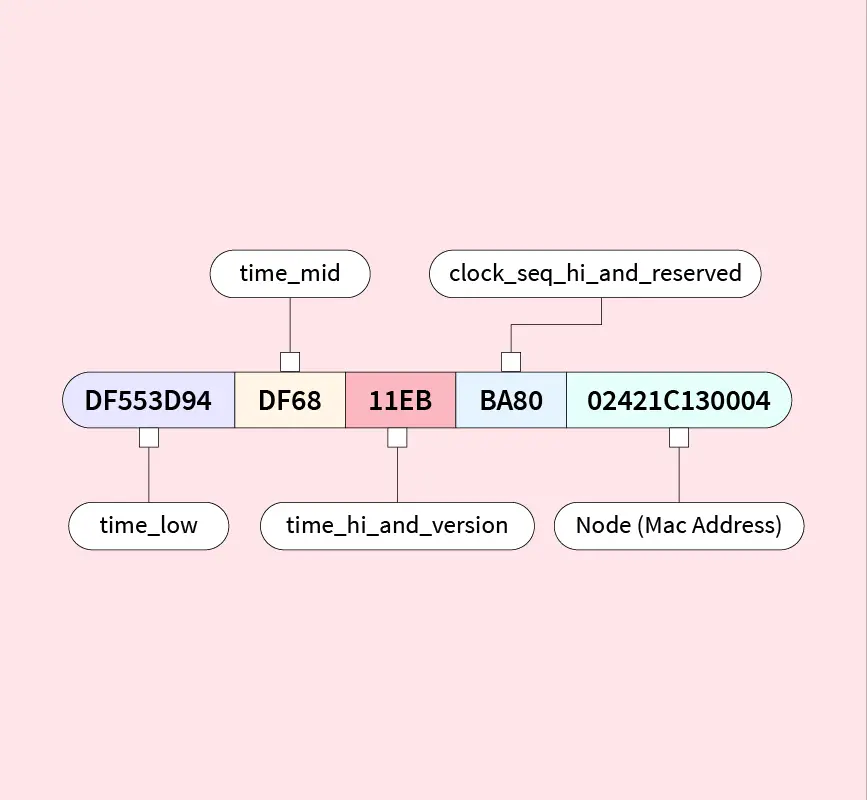
UUID(Universally Unique Identifier)는 고유한 식별자를 생성하는 방법으로, 데이터베이스 테이블의 기본 키로 자주 사용됩니다. 이는 분산 시스템 간에 쉽게 공유 가능하며 고유성을 보장합니다. 하지만 UUID의 크기는 128비트로 상당히 크기 때문에, 기본 키로 사용하기에 적합한지에 대한 의문이 있을 수 있습니다. 그렇지만 많은 경우 선택의 여지가 없습니다.
PostgreSQL에서 UUID 데이터 타입 사용하기
PostgreSQL은 UUID를 저장하기 위한 전용 데이터 타입인 `uuid`를 제공합니다. 이는 128비트 데이터 타입으로, 하나의 값을 저장하는 데 16바이트가 필요합니다. 만약 문자열로 저장하려 한다면 text 타입을 사용할 수도 있지만, text 타입은 UUID를 저장하기에 적합하지 않습니다. 실험 결과, text 타입을 사용하는 테이블은 UUID 타입을 사용하는 테이블보다 54% 더 크고, 인덱스 크기는 85% 더 큽니다.
UUID와 B-Tree 인덱스의 관계
B-Tree 인덱스는 순서가 있는 값과 잘 작동하지만, 랜덤 UUID는 B-Tree 인덱스에 적합하지 않습니다. Java의 `UUID.randomUUID()`는 UUID v4를 반환하며, 이는 의사 랜덤 값입니다. 반면, UUID v7은 시간 순서대로 정렬된 값을 생성하여 B-Tree 인덱스에 적합합니다. 이를 통해 삽입 성능을 향상시킬 수 있습니다.
UUID v7 사용하기
Java에서 UUID v7을 사용하려면 `java-uuid-generator` 라이브러리가 필요합니다. UUID v7을 생성하면 삽입 성능이 약 2배 더 빠릅니다. 실험 결과, UUID v7을 사용하는 테이블은 10,000개의 행을 10번 삽입할 때 UUID v4보다 성능이 약 2배 더 향상되었습니다.
최적화 필요성
대규모 데이터셋이나 높은 트래픽이 예상된다면 최적화를 고려해야 합니다. 기본 키 변경은 어려운 작업이므로 처음부터 올바르게 설정하는 것이 중요합니다. 최적화가 이루어져도 UUID는 기본 키로서 최적의 타입이 아닐 수 있습니다. 선택의 여지가 있다면 TSID와 같은 다른 옵션을 고려해볼 만합니다.
결론
UUID를 기본 키로 사용하는 것은 많은 이점이 있지만, 성능 최적화가 필요합니다. UUID v7을 사용하면 삽입 성능을 크게 향상시킬 수 있으며, PostgreSQL에서 UUID를 효율적으로 사용할 수 있는 방법을 고민해볼 필요가 있습니다. 대규모 데이터셋이나 높은 트래픽이 예상되는 경우, 처음부터 올바르게 설정하는 것이 매우 중요합니다.
PostgreSQL에서의 데이터베이스 최적화는 여러분의 시스템 성능을 극대화하는 데 중요한 요소입니다. 지금 바로 UUID v7을 도입하여 성능을 높여보세요.
참고 자료: Maciej Walkowiak