
이 글은
yunwoong님의 티스토리 블로그
포스트를 참고하였습니다.
Tesseract란
테서랙트는 다양한 운영 체제를 위한 광학 문자 인식 엔진으로, 이 소프트웨어는 Apache License, v2.0에 따라 배포되는 무료 소프트웨어입니다. 테서랙트는 1995년에 문자 정확도 측면에서 3대 OCR 엔진에 속했는데, 2006년부터 Google에서 개발을 후원했고, Linux, Windows 및 Mac OS X에서 사용할 수 있습니다.
테서랙트는 v2 이하에서는 간단한 단일 열 텍스트의 TIFF 이미지만 입력으로 허용했지만, v3 부터는 출력 텍스트 형식, OCR 위치 정보 및 페이지 레이아웃 분석을 지원하게 되었고, Leptonica 라이브러리를 사용한 여러 가지 새로운 이미지 형식에 대한 지원이 추가되었습니다. 현재는 많은 언어 및 스크립트에 대한 LSTM 기반 OCR 엔진 및 모델이 추가되어 총 116개의 언어가 제공되고 있습니다.
Tesseract, PyTesseract 설치하기
1. Tesserct Engine 설치
Windows에 Tesseract를 설치하기 위해, Windows용 Tesseract 설치 프로그램을 github 페이지에 접속하여 다운로드합니다.
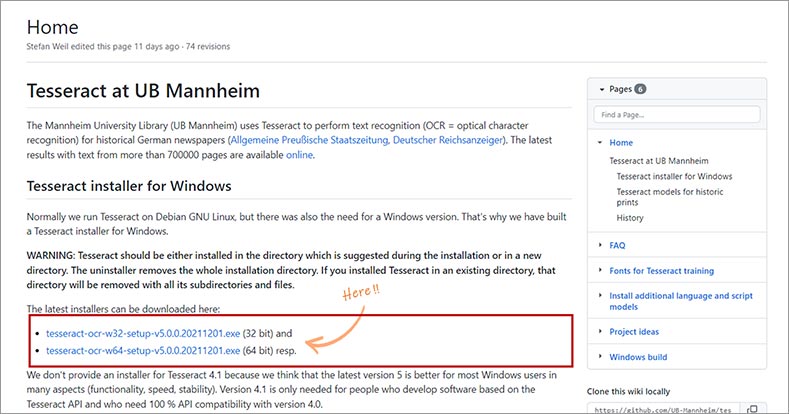
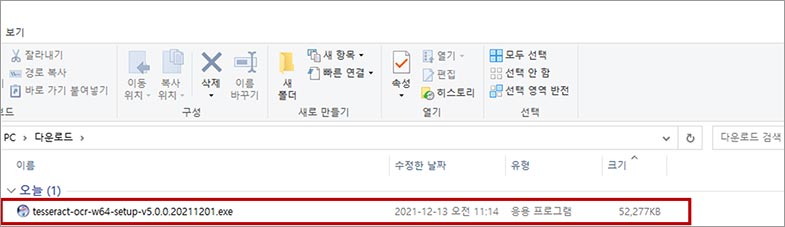
다운로드 받은 설치 파일을 실행합니다.
언어 선택에서 한국어를 추가합니다.
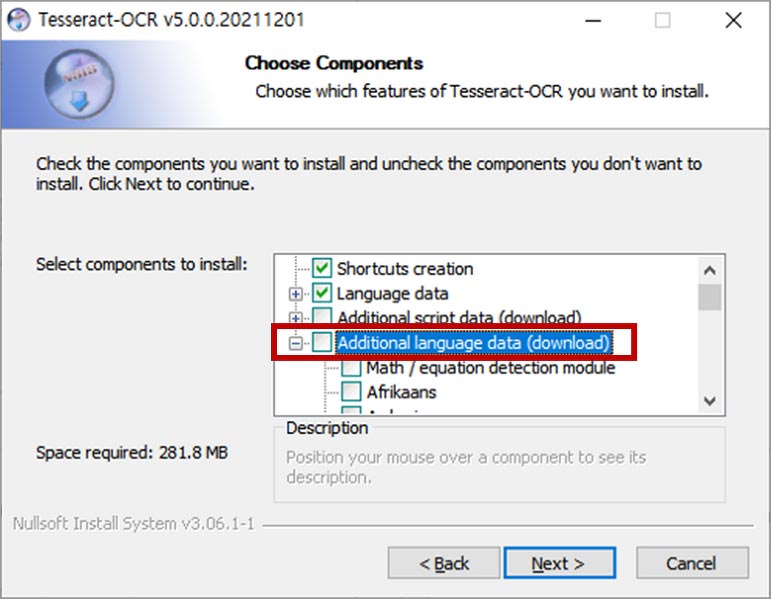
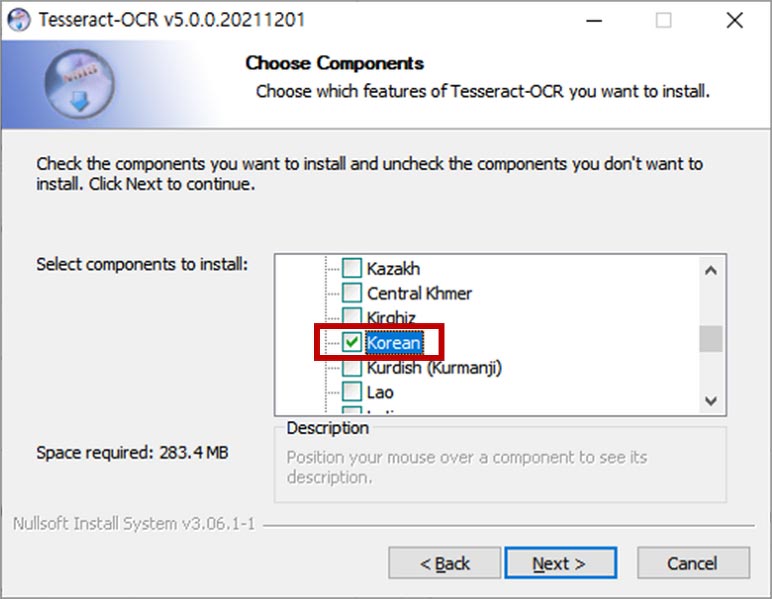
참고로, 5.0 이전에는 환경변수에 Path를 추가하는 옵션이 있었는데, 자동으로 추가하면 일부 PC에서 문제가 발생하는 경우가 있어, 5.0부터는 없어졌다고 합니다. 그래서 만약 Python에서 직접 경로를 입력하고 사용하고 싶지 않다면, 수동으로 환경변수에 Path를 추가해 주어야 합니다.

2. Path 추가하기
우선 테서랙트의 설치 경로를 확인하여 복사합니다.
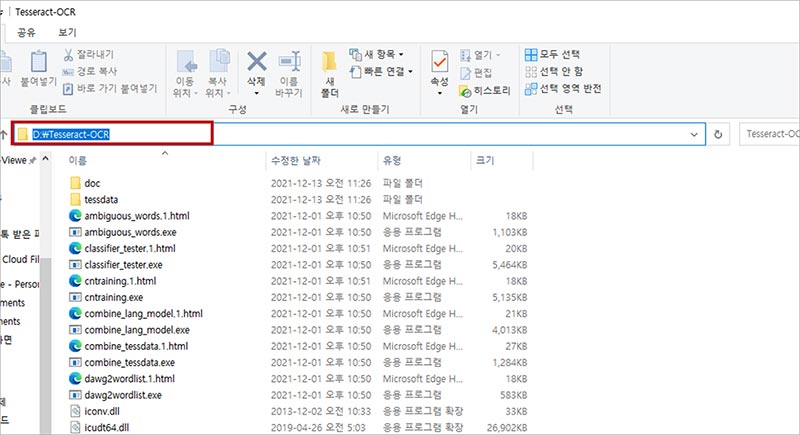
고급 시스템 설정 > 고급 > 환경 변수로 이동 한 후,
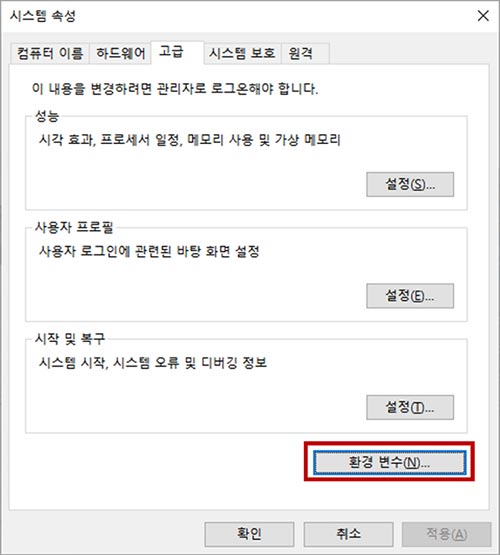
Path에 Tesseract 경로를 추가해 줍니다.
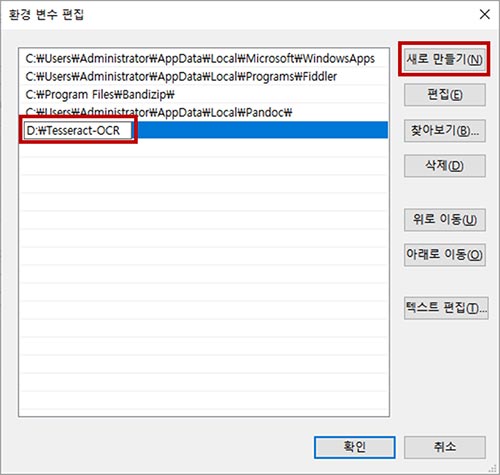
경로를 추가한 후, 윈도우의 프롬프트 창을 열어 tesseract 명령어를 입력합니다. 환경변수가 정상저으로 설정되었다면, 다음과 같이 출력됩니다.
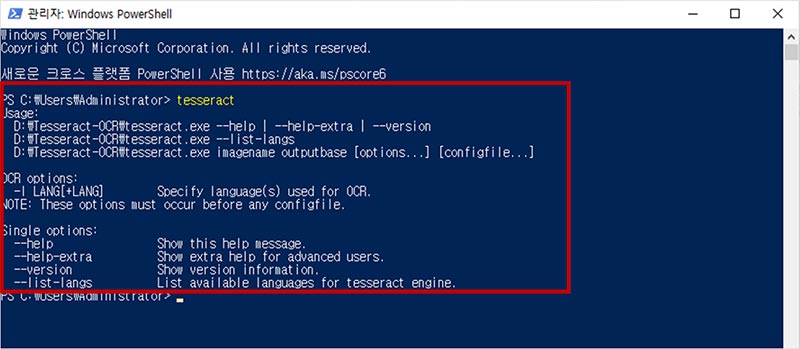
3. OpenCV와 PyTesseract 설치
파이썬의 PyTesseract와 필요한 패키지를 설치합니다.
pip install numpy pip install opencv-contrib-python pip install pytesseract
이렇게 Tesseract OCR 엔진과 OCR 및 컴퓨터 비전과 이미지 처리를 수행하기 위한 필수 Python 패키지 설치가 완료되었습니다.
Tesseract OCR 구현하기
OCR은 차량의 번호판이나 카드번호와 같이 이미지의 텍스트를 읽는 기술을 뜻하는데, OCR의 역사는 생각보다 매우 길다고 합니다.
OCR은 1928년에 독일의 G. Taushek가 미리 준비된 몇 개의 표준 pattern 문자와 입력 문자를 비교하여 표준 pattern 문자와 가장 유사한 것을 해당 문자로 선정하는 pattern matching 기법을 이용한 문자 인식 방법을 특허로 등록하면서 시작되었다고 합니다.
물론 기술 개발의 역사는 오래되었지만 아직 충분한 성능을 발휘하지는 못하고 있는데, 특히 종이 서류 또는 한글 언어 등의 인식률은 매우 낮은 상태입니다. 하지만 잘 사용하면 생각보다 유용한 기술이기도 한데, 파이썬에서는 다음과 같이 관련 패키지를 임포트하면 가장 기본적인 OCR 기능을 쉽게 구현할 수 있습니다.
import pytesseract import cv2 import matplotlib.pyplot as plt path = f'asset/images/image.jpg' image = cv2.imread(path) rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) text = pytesseract.image_to_string(rgb_image, lang='kor+eng') print(text)

YouDad(?-54) 꼭 들려주고 싶은 이야기들 https:/Awww.youdad.kr
OCR을 구현한 후 테스트를 해보면, 위의 이미지와 같이 단순한 텍스트 이미지의 경우에도 생각보다 인식이 잘 되지 않습니다. 만약 다음 이미지 처럼 조금 더 복잡하거나, 흐리거나, 노이즈가 있는 경우에는 더욱 처참한 결과가 나오게 됩니다.

1 - WESTPORT, CT (203) 227-6888
하지만 몇 가지의 이미지 전처리 작업을 통해 더 나은 OCR 성능을 구현할 수 있는데, 이에 대해서는 윤웅님의 블로그에 자세히 소개되어 있습니다. 더 나은 OCR을 위한 이미지 전처리 작업에 대해 알고 싶다면 윤웅님의 블로그를 참고하시기 바랍니다.
참고 글 링크
- [Python] 간단한 MNIST 모델 (OCR) 만들기
- [OCR] Tesseract, PyTesseract 설치방법
- [OCR] 파이썬 Tesseract OCR 활용 (기본)
- [OCR] 파이썬 Tesseract OCR 활용 (심화1)
- [OCR] 파이썬 Tesseract OCR 활용 (심화2)
- [OCR] 문자 추출 및 인식(EAST text Detector Model)
- [OCR] EasyOCR 사용하기 – Python
- [OCR] Naver CLOVA OCR API 를 이용한 OCR 개발
- [OCR] kakaobrain pororo OCR 사용하기 – Python
- yunwoong7/korean_ocr_using_pororo