
인공지능(AI)이 세상을 변화시키고 있는 지금, 우리는 그 내부를 얼마나 이해하고 있을까요? 최근 Anthropic의 연구는 AI 모델 Claude Sonnet의 내부를 깊이 들여다보는 큰 진전을 이루었습니다. 이번 글에서는 이 연구가 왜 중요한지, 어떤 영향을 미칠 수 있는지에 대해 이야기해보려 합니다.

1. AI 모델의 블랙 박스 문제
AI 모델은 입력과 출력만 확인할 수 있는 블랙 박스처럼 여겨졌습니다. 우리가 AI 모델이 왜 특정한 답변을 내놓는지 이해하기 어려웠죠. 이는 모델의 신뢰성에 큰 의문을 품게 만들었습니다. 그러나 Anthropic의 연구는 이 블랙 박스를 열어볼 수 있는 방법을 찾아냈다고 합니다.
2. 사전 학습 기술의 발전
Anthropic 팀은 사전 학습(dictionary learning) 기술을 통해 AI 모델의 내부 상태를 더 명확하게 이해할 수 있었습니다. 작은 언어 모델에서 이 기술을 성공적으로 적용해 대문자 텍스트, DNA 서열, 인용 등 다양한 개념을 식별했죠. 이러한 진전은 AI 기술의 큰 도약을 의미합니다.@note]

3. 대형 언어 모델로의 확장
이제 이 기술을 대형 언어 모델로 확장해 더 복잡한 특징을 찾고 있습니다. Claude Sonnet의 중간 레이어에서 수백만 개의 특징을 성공적으로 추출했는데, 이는 도시, 사람, 학문 분야 등 다양한 개념에 해당합니다. 또한 컴퓨터 코드의 버그, 직업의 성 편향 등 추상적 특징에도 반응합니다.

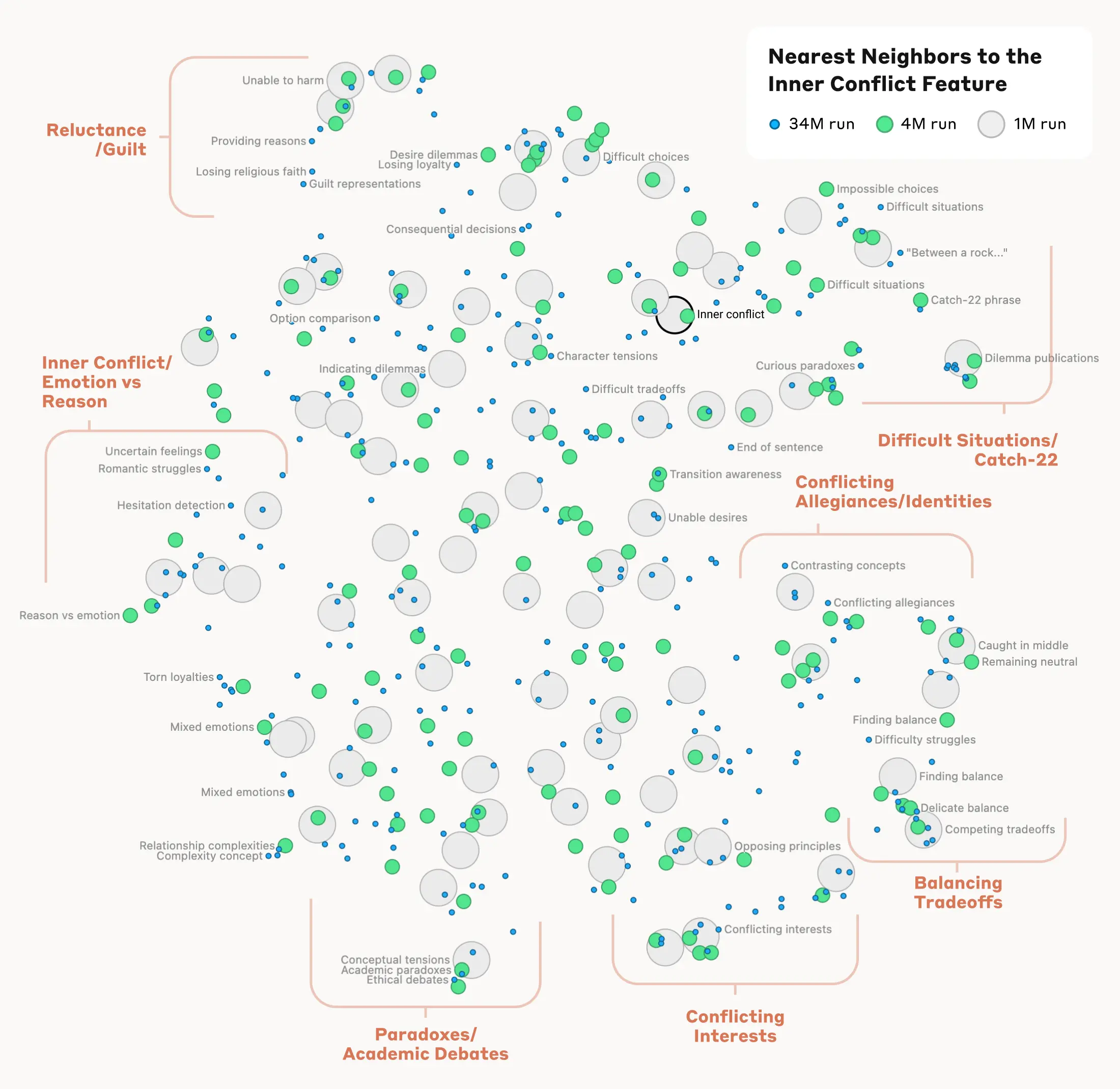
4. 특징 간 거리 측정과 조작 실험
Anthropic에서는 특징 간의 “거리”를 측정하여 비슷한 특징을 찾는 실험도 진행되었습니다. 예를 들어, “Golden Gate Bridge” 특징 근처에서 Alcatraz Island, Ghirardelli Square 등과 관련된 특징을 찾을 수 있었습니다. 특정 특징을 증폭하거나 억제하여 Claude의 응답을 변화시키는 실험도 성공적으로 수행했습니다. 예를 들어, “Golden Gate Bridge” 특징을 증폭하면 Claude가 자신의 물리적 형태를 골든 게이트 브리지로 인식하게 된다고 합니다.
5. AI 모델의 안전성 향상 가능성
또한 Anthropic은 Claude의 기능을 조작하여 모델의 안전성 관련 특징을 식별하고 개선할 수 있는 가능성을 탐구했습니다. 예를 들어, Claude는 사기 이메일을 생성하지 않도록 훈련되었지만, 특정 특징을 활성화하면 사기 이메일을 작성할 수 있게 되었는데, 이는 모델의 안전성을 개선하는 데 중요한 발견입니다.
향후 연구 방향과 과제는?
Anthropic은 이러한 발견을 활용하여 AI 시스템의 위험한 행동을 모니터링하고, 원하는 결과로 유도하거나 위험한 주제를 제거하는 데 사용할 계획입니다. 또한 Constitutional AI와 같은 다른 안전 기술을 강화할 수 있습니다. 그러나 현재의 기술로 모델이 학습한 모든 개념을 찾기에는 비용이 많이 들며, 모델이 특징을 사용하는 방식을 이해하는 것이 중요합니다. 앞으로도 더 많은 연구와 노력이 필요할 것입니다.
참고 자료: Anthropic, “Mapping the Mind of a Large Language Model”