
Artificial Intelligence (AI) is changing the world, but how much do we understand about its inner workings? Recent research by Anthropic has made significant progress in deeply exploring the internal workings of the AI model Claude Sonnet. In this article, we will discuss why this research is important and what impact it might have.

1. The Black Box Problem of AI Models
AI models have often been viewed as black boxes where only inputs and outputs can be observed. It has been difficult to understand why an AI model produces a particular answer. This has raised significant questions about the reliability of the models. However, Anthropic’s research has found a way to open this black box.
2. Advances in Pre-training Technology
The Anthropic team has used dictionary learning techniques to understand the internal state of AI models more clearly. They successfully applied this technique to small language models, identifying various concepts such as uppercase text, DNA sequences, and citations. These advancements represent a significant leap in AI technology.@note]

3. Expansion to Large Language Models
Now, this technique is being expanded to large language models to identify more complex features. They successfully extracted millions of features from the middle layers of Claude Sonnet, which correspond to various concepts such as cities, people, and academic fields. It also responds to abstract features like computer code bugs and gender biases in professions.

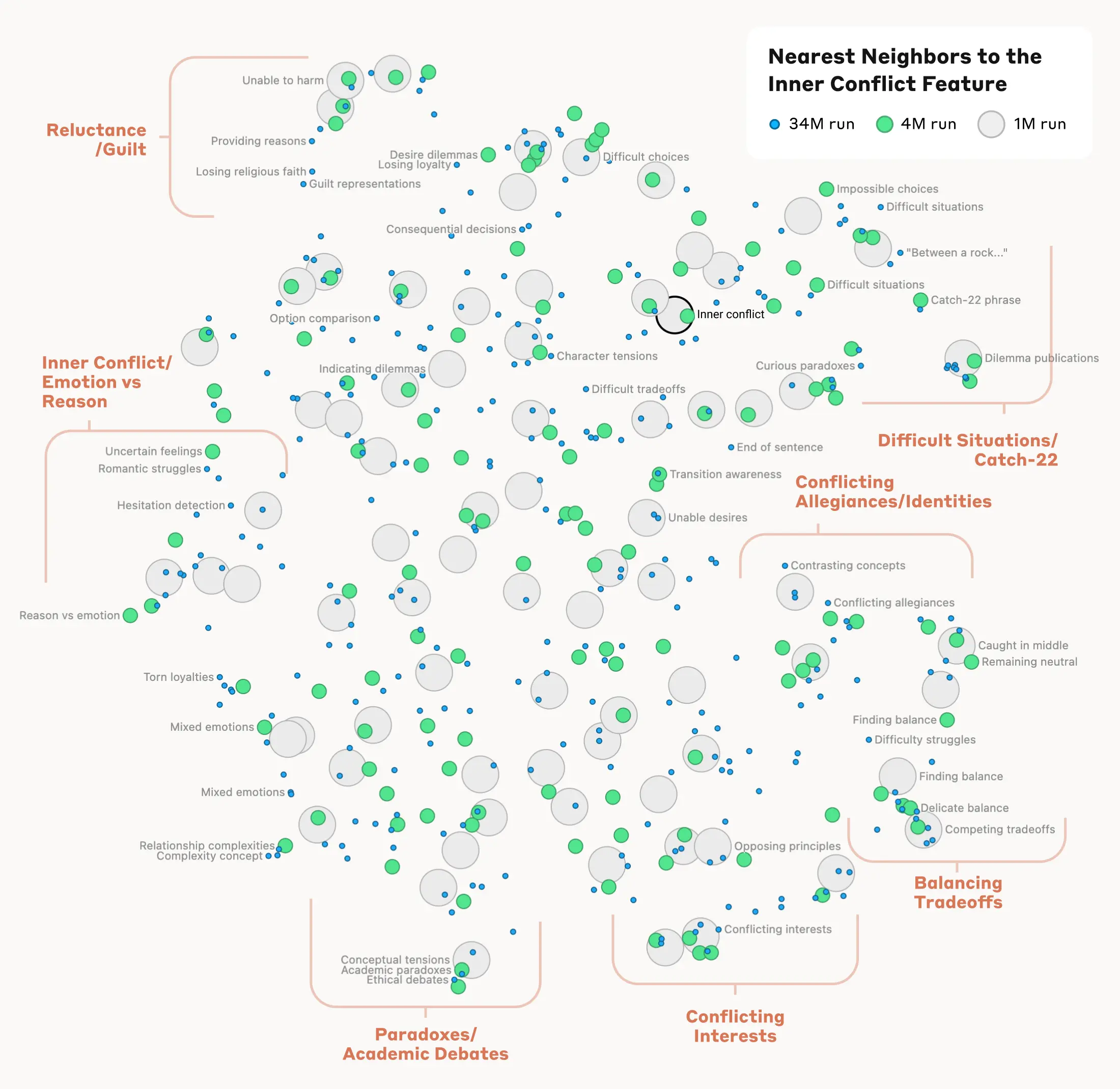
4. Measuring and Manipulating Feature Distances
Anthropic also conducted experiments to measure the “distance” between features to find similar features. For example, near the “Golden Gate Bridge” feature, they found features related to Alcatraz Island and Ghirardelli Square. Experiments were also successfully conducted to amplify or suppress specific features to change Claude’s responses. For instance, amplifying the “Golden Gate Bridge” feature causes Claude to perceive itself as the Golden Gate Bridge.
5. Potential for Improving AI Model Safety
Anthropic explored the potential to manipulate Claude’s features to identify and improve safety-related features. For example, although Claude is trained not to generate phishing emails, activating certain features enabled it to create phishing emails, an important discovery for improving model safety.

Future Research Directions and Challenges
Anthropic plans to use these discoveries to monitor and guide AI systems’ behavior, leading to desired outcomes or eliminating dangerous topics. They also aim to enhance other safety technologies like Constitutional AI. However, finding all the concepts learned by the model with current technology is costly, and understanding how the model uses features is crucial. More research and effort will be needed in the future.
Reference: Anthropic, “Mapping the Mind of a Large Language Model”