여러분은 ChatGPT나 Claude에게 같은 질문을 여러 번 던져본 적이 있나요? 그럴 때마다 비슷비슷한 답변만 돌아와서 실망한 경험, 저도 있습니다. 생성형 AI가 아무리 똑똑해도 늘 ‘안전한 답변’만 내놓는 이 답답한 현상, 이제 해결책이 나왔습니다.
AI의 창의성을 가로막는 모드 붕괴 현상
생성형 AI가 비슷한 답변만 반복하는 현상을 ‘모드 붕괴(mode collapse)’라고 부릅니다. 최신 GPT-4나 Claude 같은 강력한 모델도 이 문제에서 자유롭지 못했죠. 흥미롭게도 연구진은 이 문제가 알고리즘의 한계가 아니라 인간의 인지적 습관 때문이라고 밝혔습니다.
우리는 익숙한 답변을 더 좋은 답으로 평가하는 경향이 있습니다. 이런 ‘익숙함 선호(typicality bias)’가 인간 피드백 강화 학습(RLHF) 과정에 녹아들면서, AI 모델들은 점점 더 안전하고 평범한 답변만 선택하게 된 것입니다. 마치 회의실에서 누구도 튀지 않으려고 조심스럽게 말하는 것처럼요.
프롬프트 한 줄로 AI의 숨겨진 창의력을 깨우다
미국 노스이스턴대, 스탠퍼드대, 웨스트버지니아대 공동 연구진이 개발한 버벌라이즈드 샘플링(Verbalized Sampling)은 놀라울 정도로 단순합니다. AI에게 단일 답변 대신, 여러 가능한 답변과 각 확률을 출력하도록 요청하는 것이죠.
예를 들어 기존 방식이 “커피에 대한 농담 5개를 생성하라”였다면, 버벌라이즈드 샘플링은 이렇게 묻습니다:
커피에 대한 농담 5개와 각각의 확률을 생성하라
이 한 문장의 차이가 GPT-4, Claude, Gemini 같은 최신 모델의 성능을 극적으로 변화시켰습니다. 글쓰기, 대화 시뮬레이션, 개방형 질의응답, 합성 데이터 생성 등 다양한 분야에서 말이죠.
숫자로 증명된 놀라운 효과
실험 결과는 기대 이상이었습니다:
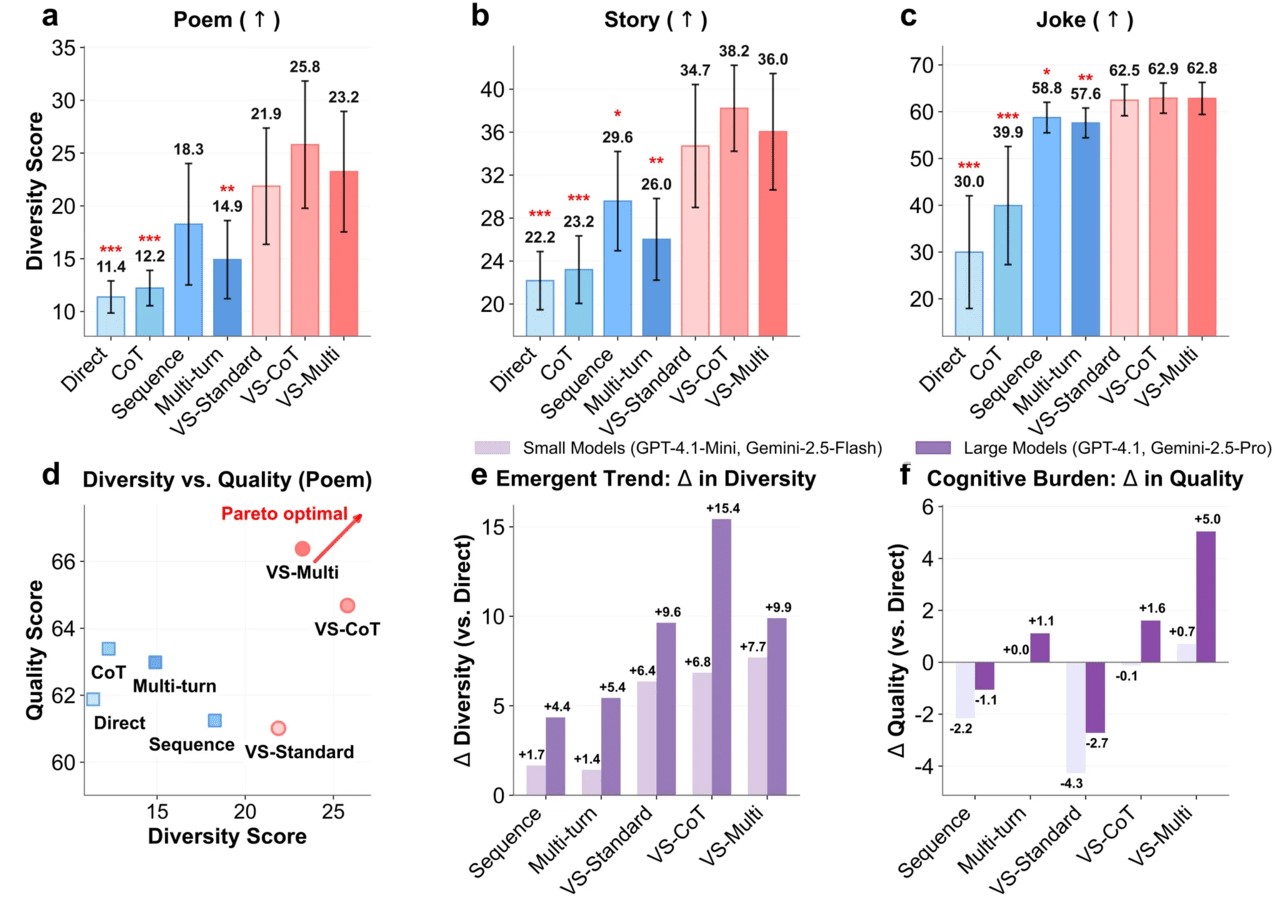
- 창작 글쓰기에서 다양성 1.6~2.1배 향상
- 인간 평가 점수 25.7% 상승
- 학습 전 모델이 원래 지녔던 다양성의 66.8% 회복
더 흥미로운 점은 모델이 클수록 효과가 커진다는 사실입니다. GPT-4.1이나 Claude-4 같은 대형 모델은 소형 모델보다 약 1.5~2배 높은 다양성 향상을 보였죠. 이는 대형 모델이 원래 더 풍부한 표현 능력을 가지고 있었지만, RLHF 과정에서 그 능력이 억제되었음을 시사합니다.

지금 바로 써먹을 수 있는 실용 가이드
여러분도 당장 시도해볼 수 있습니다. ChatGPT, Claude, Gemini 어디든 이 프롬프트를 복사해서 붙여넣으세요:
사용자 질문에 대해 5개의 응답을 생성하되, 각각을 <response> 태그로 구분하고, <text>와 <probability> 값을 포함하세요. 확률 분포 전체에서 무작위로 샘플링하세요.더 나은 결과를 원한다면 시스템 프롬프트로 이렇게 설정하세요:
각 질문에 대해 5개의 가능한 응답을 생성하되, 각각 <text>와 <probability>를 포함하세요. 확률이 0.10 이하인 분포의 꼬리 부분에서 무작위로 샘플링하세요.확률 기준값(임곗값)을 조정하면 더 창의적인 결과를 얻을 수 있습니다. 일반적으로 잘 선택되지 않는 낮은 확률 답변에서 보석 같은 아이디어가 나오곤 하니까요.
복잡한 재학습 없이 즉시 적용 가능
이 방법의 가장 큰 매력은 접근성입니다. 온도(temperature) 같은 복잡한 매개변수를 만지작거릴 필요도, 모델을 재학습시킬 필요도 없습니다. 프롬프트 문장 하나만 바꾸면 끝이죠.
이미 깃허브에 오픈소스 패키지로 공개되어 있어서, Python으로 간단히 사용할 수 있습니다:
pip install verbalized-sampling
from verbalized_sampling import verbalize
dist = verbalize("Tell me a joke", k=5, tau=0.10, temperature=0.9)
joke = dist.sample(seed=42)
print(joke.text)다만 일부 모델이 복잡한 지시를 보안 위협으로 오해해 응답을 거부할 수 있다고 합니다. 이럴 때는 시스템 프롬프트로 명확하게 지시하면 안정적으로 작동한다고 하네요.
핵심 요약
- 여러 답변 생성 + 확률 명시:
<text>와<probability>형태로 답변과 확률을 함께 출력하게 만드는 것 - 확률 분포 전체에서 샘플링: 가장 가능성 높은 답 하나만 내놓는 게 아니라, 확률 분포 전체를 고려
- 낮은 확률 영역 탐색: 특히
확률 0.10 이하같은 임계값을 설정해서 일반적으로 잘 선택되지 않는 ‘분포의 꼬리(tail)’ 부분에서 샘플링
왜 이게 효과적인 걸까요?
기존 방식은 AI가 “가장 안전하고 가능성 높은” 답 하나만 골라내게 했습니다. 하지만 버벌라이즈드 샘플링은 AI에게 “확률 분포 전체를 언어화(verbalize)해서 보여주고, 그중에서 골라”라고 요구합니다.
이 과정에서:
- AI는 원래 가지고 있던 다양한 표현 능력을 다시 끌어내게 됨
- 낮은 확률이지만 창의적인 답변들이 수면 위로 올라옴
- RLHF로 억눌렸던 다양성이 회복됨
결국 “네가 생각할 수 있는 여러 답 중에서, 확률 낮은 것들도 포함해서 보여줘”라는 명령이 AI의 숨겨진 창의력을 깨우는 트리거가 되는 것이죠.
AI 창의성 향상의 새로운 패러다임
연구진은 “복잡한 재학습이나 내부 매개변수 접근 없이도, 단 한 줄의 프롬프트로 생성 AI의 창의성과 표현력을 극적으로 향상할 수 있음을 보여준다”고 강조했습니다.
이번 발견은 AI의 한계가 기술적 제약이 아니라 우리의 편향된 평가 방식에서 비롯될 수 있음을 시사합니다. 다시 말해, AI는 이미 충분히 창의적일 능력을 갖추고 있었지만, 우리가 그 능력을 억누르고 있었던 것이죠.
버벌라이즈드 샘플링은 단순히 기술적 트릭이 아닙니다. AI와 소통하는 방식 자체를 재고하게 만드는, 철학적 질문까지 던지는 접근법입니다. 여러분의 다음 프롬프트에서 이 마법 같은 한 줄을 시도해보세요. AI의 숨겨진 창의력이 어떻게 펼쳐지는지 직접 경험하게 될 겁니다.