
클라우드 컴퓨팅의 세계에서 AWS S3는 단연 최고의 스토리지 서비스로 인정받고 있습니다. 하지만 여러분은 이 거대한 시스템이 구식 하드디스크 드라이브(HDD) 위에서 초당 1페타바이트라는 상상을 초월하는 처리량을 달성하고 있다는 사실을 알고 계시나요?
이 글에서는 AWS S3가 물리적 한계를 극복하고 현대 인터넷의 백본이 된 혁신적인 아키텍처를 자세히 살펴보겠습니다.
S3의 놀라운 규모: 숫자로 보는 현실
AWS S3의 규모는 그야말로 상상을 초월합니다. 현재 S3는 400조 개 이상의 객체를 저장하고 있으며, 초당 1억 5천만 건의 요청을 처리합니다. 피크 시에는 초당 1페타바이트 이상의 트래픽을 지원하며, 이 모든 것이 수천만 개의 하드디스크 위에서 돌아가고 있습니다.
이런 규모의 시스템이 구식 기술로 여겨지는 HDD를 기반으로 한다는 것은 언뜻 모순적으로 보입니다. 하지만 여기에는 경제성과 기술적 혁신이 절묘하게 결합된 AWS의 전략이 숨어있습니다.
HDD의 경제성: 여전히 유효한 선택
가격 혁명의 역사
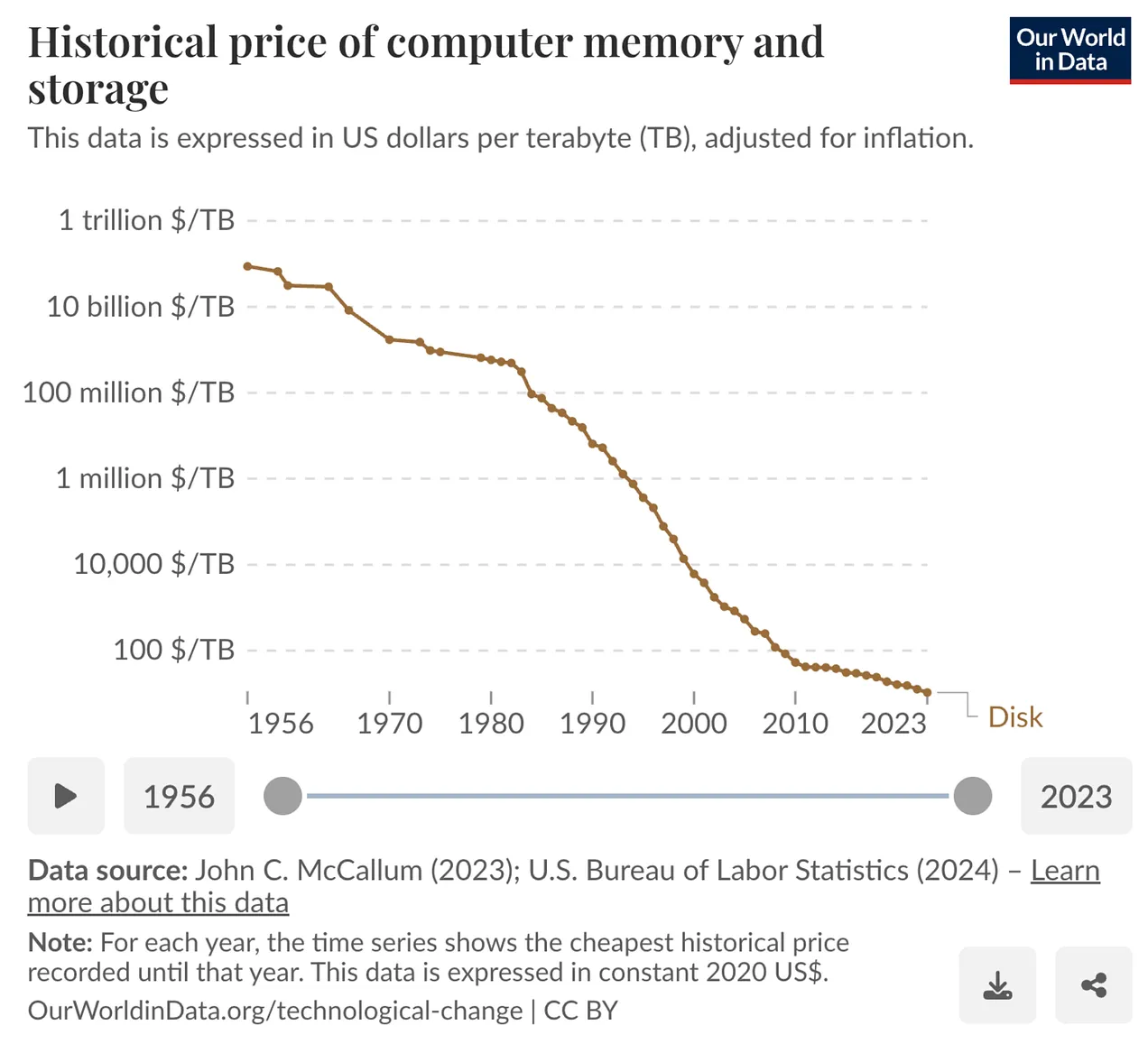
HDD는 지난 수십 년 동안 놀라운 가격 하락을 경험했습니다. 물가 반영 기준으로 바이트당 가격이 60억 배 하락했고, 용량은 720만 배 증가, 크기는 5천 배 감소, 무게는 1,235배 감소했습니다.
하지만 한 가지 변하지 않은 것이 있습니다. 바로 IOPS(초당 입출력) 성능입니다. 30년 동안 약 120 IOPS 수준에 머물러 있어, 용량 대비 성능은 오히려 떨어지고 있는 상황입니다.
물리적 한계의 벽
HDD가 느린 이유는 물리학적 한계 때문입니다. SSD와 달리 HDD는 기계적 움직임이 필요합니다:
- 시킹 시간: 액추에이터가 플래터를 가로질러 이동하는 시간 (평균 4ms)
- 회전 지연: 플래터가 회전하여 정확한 위치에 도달하는 시간 (평균 4ms)
- 전송 시간: 실제 데이터를 읽어들이는 시간 (0.5MB 당 약 2.5ms)
결과적으로 0.5MB의 랜덤 읽기에는 평균 11ms가 소요되며, 단일 디스크의 랜덤 처리량은 약 45MB/s에 불과합니다.
S3의 해법: 대규모 병렬화 전략
1. 로그 구조 최적화
S3의 내부 저장 계층인 ShardStore는 LSM(로그 구조 병합 트리)을 채택했습니다. 이를 통해 쓰기 작업을 디스크의 순차 append로 처리하여 HDD의 순차 접근 특성을 최대한 활용합니다.
카프카와 같은 시스템이 로그 기반 구조로 뛰어난 성능을 내는 것처럼, S3도 배치 처리를 통해 디스크의 순차 처리량을 극대화합니다.
2. Erasure Coding을 통한 병렬 처리
S3는 5-of-9 Erasure Coding 방식을 사용합니다:
- 5개의 데이터 샤드 + 4개의 패리티 샤드 = 총 9개 조각
- 최대 4개 샤드 손실까지 복원 가능
- 저장 오버헤드는 약 1.8배로 3중 복제(3배) 대비 효율적
- 5개의 병렬 읽기 경로 확보로 성능 향상
예를 들어, 1TB 파일을 2만 개의 HDD에 분할 저장하면 각 디스크의 처리량을 합산하여 TB/s급 읽기가 가능해집니다.
3단계 병렬화 아키텍처
1. 프론트엔드 서버 병렬 처리
HTTP 커넥션 풀을 활용해 분산된 여러 엔드포인트에 동시 연결하여 특정 인프라 노드의 과부하를 방지합니다.
2. 하드 드라이브 간 병렬 처리
Erasure Coding을 기반으로 데이터를 여러 HDD에 소규모 샤드로 분산 저장합니다.
3. PUT/GET 요청 병렬 처리
- PUT: 멀티파트 업로드로 병렬 처리 극대화
- GET: 바이트 레인지 GET으로 객체 내 일부 범위만 읽기 가능
이러한 병렬 처리를 통해 초당 1GB 업로드도 어려움 없이 달성할 수 있습니다.
핫스팟 방지: 지능적 로드 밸런싱
1. 셔플 샤딩 & Power of Two
Power of Two Random Choices 알고리즘을 적용합니다:
- 무작위로 선택한 2개 노드 중 부하가 적은 쪽을 선택
- 단순 랜덤 선택보다 훨씬 효과적인 로드 밸런싱 실현
2. 지속적 리밸런싱
데이터 온도(신규 데이터가 더 자주 접근됨) 특성을 활용:
- 주기적 리밸런싱으로 공간과 I/O 재분배
- 신규 랙 도입 시 빈 용량에 능동적 분산
3. Chill@Scale: 규모의 효과
시스템이 클수록 워크로드 독립성으로 인한 데코릴레이션 효과 발생:
- 버스트 동시성 감소로 집계 부하 평탄화
- 피크/평균 격차 축소로 예측 가능성 향상
현대 아키텍처에 미치는 영향
S3의 성공은 Stateless 아키텍처 확산으로 이어졌습니다. 많은 시스템들이 상태를 비우고 영속성, 복제, 부하분산을 S3에 위임하는 패턴을 채택하고 있습니다:
- Kafka Diskless (KIP-1150): 디스크 없는 카프카 구현
- SlateDB: S3 기반 임베디드 데이터베이스
- Lucene on S3: 검색 인덱스의 클라우드 저장
- ClickHouse/OpenSearch/Elastic: 오브젝트 스토리지 통합
이러한 접근의 장점은 탄력적 스케일링, 운영 단순화, 비용 절감이며, 단점은 지연 증가 가능성입니다.
미래를 향한 통찰
AWS S3의 사례는 우리에게 중요한 교훈을 줍니다. 최신 기술이 항상 최적의 해답은 아니라는 것입니다. 때로는 구식 기술의 장점을 극대화하는 혁신적 아키텍처가 더 효과적일 수 있습니다.
S3는 느린 저장 매체의 한계를 대규모 병렬성, 로드 밸런싱, 데이터 샤딩 기술로 극복했습니다. 이는 단순히 기술적 성취를 넘어 경제성과 성능의 절묘한 균형을 보여주는 엔지니어링의 걸작입니다.
여러분의 시스템 설계에서도 최신 기술에만 의존하기보다는, 기존 기술의 특성을 깊이 이해하고 창의적으로 활용하는 방법을 고민해보시기 바랍니다. 때로는 그것이 더 혁신적인 결과를 가져올 수 있습니다.
참고 자료: Stanislav Kozlovski, “how AWS S3 serves 1 petabyte per second on top of slow HDDs”